Inversion-based Style Transfer with Diffusion Models
Our key idea is to learn the artistic style directly from a single painting and then guide the synthesis without providing complex textual descriptions. Specifically, we perceive style as a learnable textual description of a painting. We propose an inversion-based style transfer method (InST), which can efficiently and accurately learn the key information of an image, thus capturing and transferring the artistic style of a painting.
Introduction
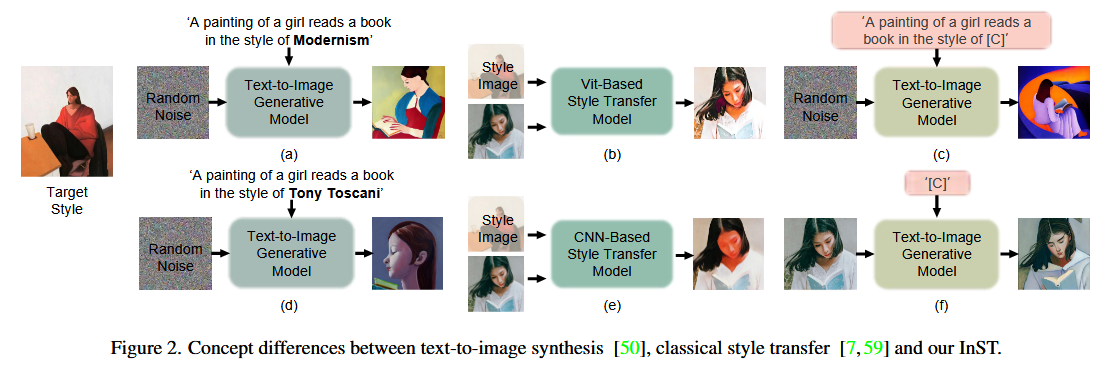
In this paper, we propose a novel example-guided artistic image generation framework (i.e., inversion-based style transfer, InST) which related to style transfer and text-to-image synthesis. Given only a single input painting image, our method can learn and transfer its style to a natural image with a very simple text prompt.

To achieve this goal, we need to obtain the representation of the image style, which refers to the set of attributes that appear in the high-level textual description of the image. We define the textual descriptions as “new words” that do not exist in the normal language and obtain the embeddings via inversion method.
Specifically, we propose an efficient and accurate textual inversion based on the attention mechanism, which can quickly learn key features from an image, and a stochastic inversion to maintain the semantic of the content image.
Method
As shown in Figure 3, our method involves the pixel, latent, and textual spaces. During training, image $x$ is the same as image $y$. The image embedding of image $x$ is obtained by the CLIP image encoder and then sent to the attention-based inversion module.
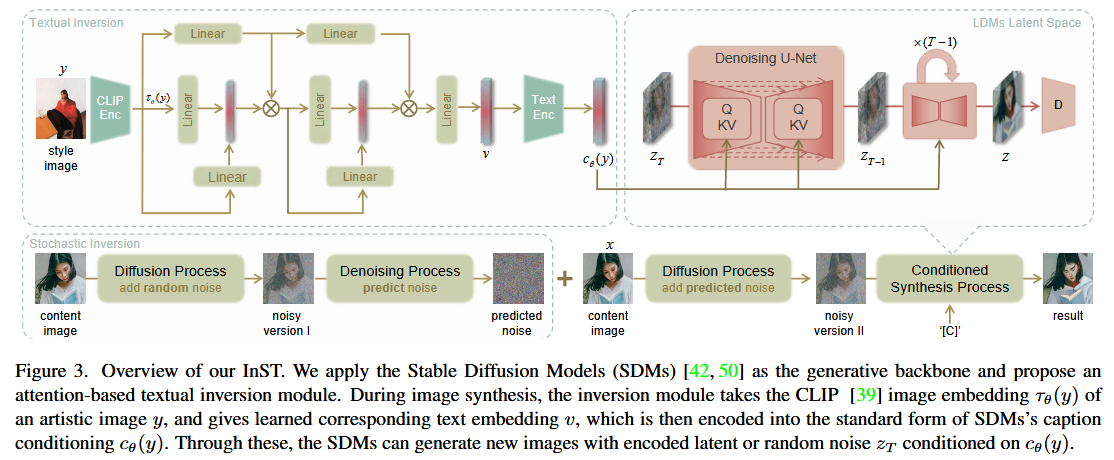
Textual Inversion
Details about textual inversion referring to An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion. However, this optimization-based approach is inefficient, and accurate embeddings are difficult to obtain without overfitting with a single image as training data.
We propose a learning method based on multi-layer cross attention. The image encoder $\tau_θ$ projects y to an image embedding $\tau_\theta(y)$. The multi-layer cross attention starts with $v_0 = \tau_\theta(y)$. Then each layer implements $Attention$ as follows:
$$
Q_i = W_Q^{(i)} \cdot v_i, K = W_K^{(i)} \cdot \tau_\theta(y), V = W_V^{(i)} \cdot \tau_\theta(y) \tag{1}
$$
$$
v_{i+1} = Attention (Q_i, K, V) \tag {2}
$$
During training, the model is conditioned by the corresponding text embedding only. To avoid overfitting, we apply a dropout strategy in each cross-attention layer, which is set to 0.05. Our optimization goal can finally be defined as follows:
$$
\hat{v} = \mathop{\arg\min}_v \mathbb{E}_{z, x, y, t}\left[ \Vert \epsilon - \epsilon_\theta(z_t, t, MultiAtt(\tau_\theta(y))) \Vert^2_2 \right] \tag{3}
$$
where $z ∼ E(x)$, $\epsilon ∼ \mathcal N (0, 1)$. $\tau_θ$ and $\epsilon_θ$ are fixed during training. In this manner, $\hat v$ is efficiently optimized to the target area.
Stochastic Inversion
We divide pre-trained text-to-image diffusion model-based image representation into two parts: holistic representation and detail representation. Holistic representation involves text conditions, and the detail representation is controlled by random noise.
We first add random noise to the content image and then use the denoising U-Net in the diffusion model to predict the noise in the image. The predicted noise is used as the initial input noise during generation to preserve the content.
Specifically, for each image $z$, the stochastic inversion module takes the image latent code $z = E(y)$ as input. Then $z_t$, the noisy version of $z$, is set as computable parameters, and $\epsilon_t$ is obtained as follows:
$$
\hat{\epsilon_t} = (z_{t-1} - \mu_T(z_t, t))\sigma_t \tag{4}
$$
Experiments
Comparison with Style Transfer Methods

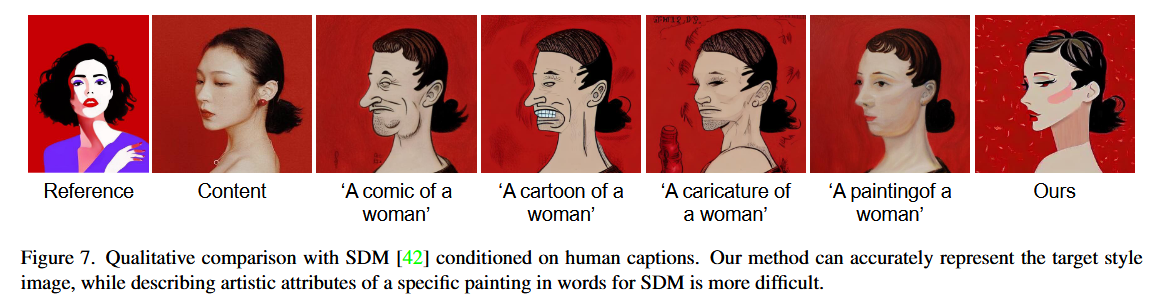
Comparison with Text-Guided Methods
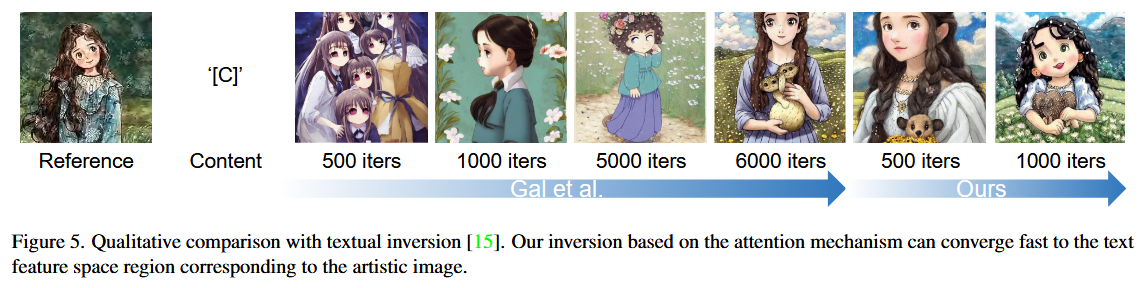

Ablation Study
Stochastic inversion: The full model can maintain the content information and reduce the impact of the style image’s semantic.
Hyper-parameter Strength: The larger the Strength, the stronger the influence of the style image on the generated result, vice versa, the generated image is closer to the content image.
Attention module: The multi-layer attention helps the content of the generated image be better controlled by the input text conditions and improves editability.
Dropout: By dropping the parameters of the latent embeddings, both the accuracy and the editability are improved.

Limitations
Although our method can transfer typical colors to some extent, when a significant difference exists between the colors of the content and reference images, our method may fail to semantically transfer the color in a one-to-one correspondence.
References
[1]: Y. Zhang et al., “Inversion-based Style Transfer with Diffusion Models,” 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 2023, pp. 10146-10156, doi: 10.1109/CVPR52729.2023.00978.
Inversion-based Style Transfer with Diffusion Models
https://breynald.github.io/2024/09/28/Inversion-based-Style-Transfer-with-Diffusion-Models/