An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Text-to-image models offer unprecedented freedom to guide creation through natural language. Yet, it is unclear how such freedom can be exercised to generate images of specific unique concepts, modify their appearance, or compose them in new roles and novel scenes. In other words, we ask: how can we use language-guided models to turn our cat into a painting, or imagine a new product based on our favorite toy?
Introduction
This paper propose to overcome these challenges by finding new words in the textual embedding space of pre-trained text-to-image models. We consider the first stage of the text encoding process. Here, an input string is first converted to a set of tokens. Each token is then replaced with its own embedding vector, and these vectors are fed through the downstream model. The goal is to find new embedding vectors that represent new, specific concepts.

In summary, our contributions are as follows:
- We introduce the task of personalized text-to-image generation, where we synthesize novel scenes of user-provided concepts guided by natural language instruction.
- We present the idea of “Textual Inversions” in the context of generative models. Here the goal is to find new pseudo-words in the embedding space of a text encoder that can capture both high-level semantics and fine visual details.
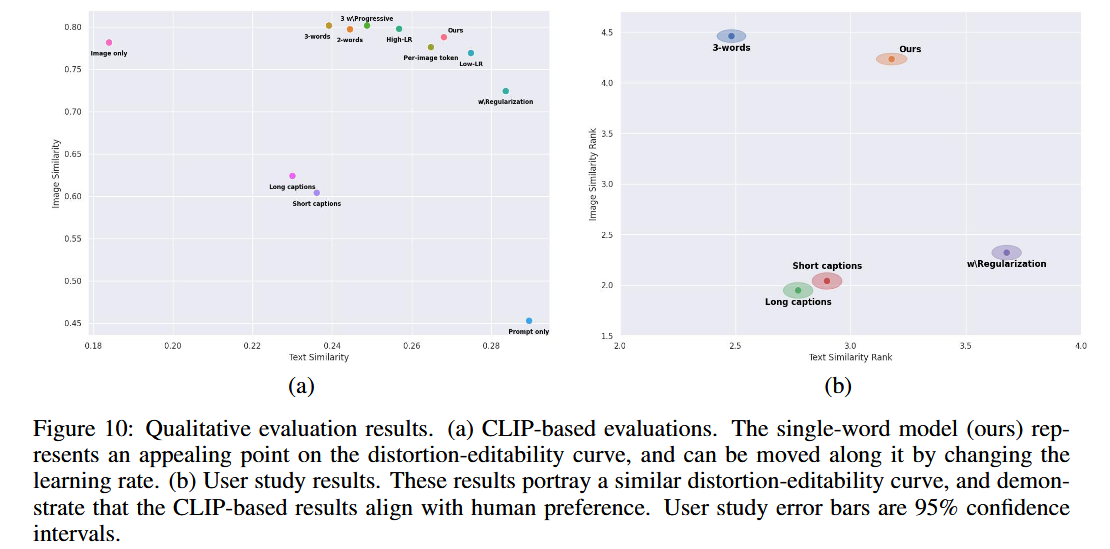
- We analyze the embedding space in light of GAN-inspired inversion techniques and demonstrate that it also exhibits a tradeoff between distortion and editability. We show that our approach resides on an appealing point on the tradeoff curve.
- We evaluate our method against images generated using user-provided captions of the concepts and demonstrate that our embeddings provide higher visual fidelity, and also enable more robust editing.
Method
Our goal is to find pseudo-words that can guide generation, which is a visual task. As such, we propose to find them through a visual reconstruction objective.
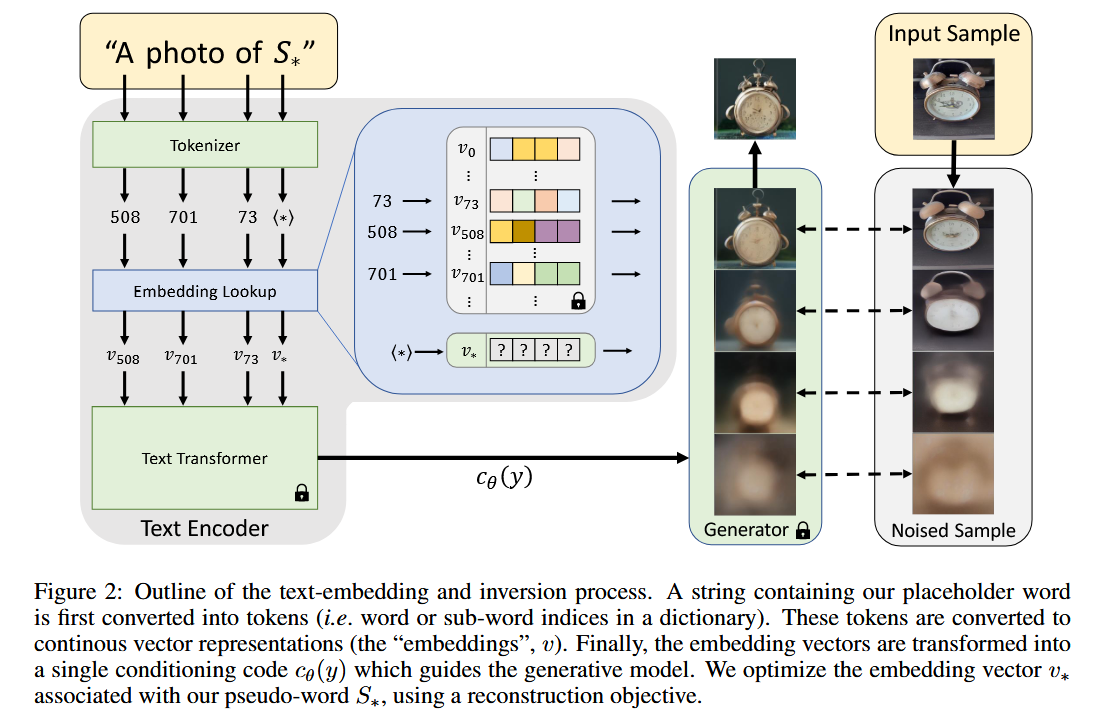
Typical text encoder models, such as BERT, begin with a text processing step. These embedding vectors are typically learned as part of the text encoder $c_θ$. In our work, we choose this embedding space as the target for inversion. Specifically, we designate a placeholder string,$S_∗$, to represent the new concept we wish to learn.
To find these new embeddings, we use a small set of images (typically 3-5), which depicts our target concept across multiple settings such as varied backgrounds or poses. We find $v_∗$ through direct optimization, by minimizing the LDM loss over images sampled from the small set. To condition the generation, we randomly sample neutral context texts, derived from the CLIP ImageNet templates (Radford et al., 2021). These contain prompts of the form “A photo of $S_∗$”, “A rendition of $S_∗$”, etc. The full list of templates is provided in the supplementary materials.
Qualitative comparisons and applications
Image variations
In contrast, our method can successfully capture these finer details, and it does so using only a single word embedding. However, note that while our creations are more similar to the source objects, they are still variations that may differ from the source.

Text-guided synthesis
As our results demonstrate, the frozen text-to-image model is able to jointly reason over both the new concepts and its large body of prior knowledge, bringing them together in a new creation.

Style transfer
typical use-case for text-guided synthesis is in artistic circles, where users aim to draw upon the unique style of a specific artist and apply it to new creations. Here, we show that our model can also find pseudowords representing a specific, unknown style.

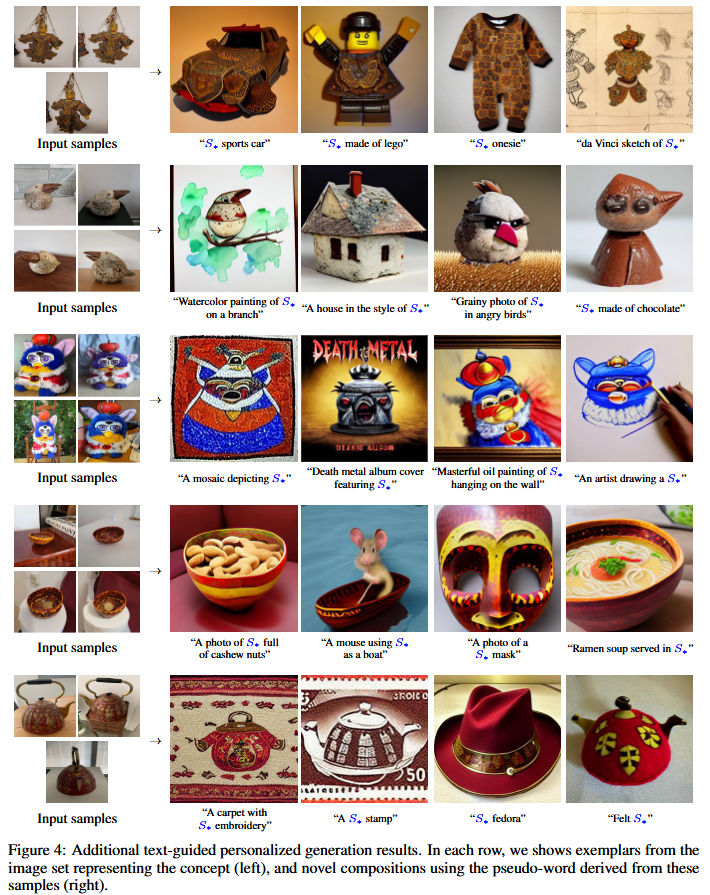
Concept compositions
In Figure 7 we demonstrate compositional synthesis, where the guiding text contains multiple learned concepts. We observe that the model can concurrently reason over multiple novel pseudo-words at the same time. However, it struggles with relations between them (e.g. it fails to place two concepts side-by-side). We hypothesize that this limitation arises because our training considers only single concept scenes, where the concept is at the core of the image. Training on multi-object scenes may alleviate this shortcoming. However, we leave such investigation to future work.

Bias reduction
A common limitation of text-to-image models is that they inherit the biases found in the internet-scale data used to train them. Here, we demonstrate that we can utilize a small, curated dataset in order to learn a new “fairer” word for a biased concept, which can then be used in place of the original to drive a more inclusive generation.

Downstream applications
Finally, we demonstrate that our pseudo-words can be used in downstream models that build on the same initial LDM model. Specifically, we consider the recent Blended Latent Diffusion (Avrahami et al., 2022a) which enables localized text-based editing of images via a mask-based blending process in the latent space of an LDM. In Figure 9 we demonstrate that this localized synthesis process can also be conditioned on our learned pseudo-words, without requiring any additional modifications of the original model.

Quantitative analysis
Evaluation metrics
To analyze the quality of latent space embeddings, we consider two fronts: reconstruction and editability.
- As our method produces variations on the concept and not a specific image, we measure similarity by considering semantic CLIP-space distances. Specifically, for each concept, we generate a 64 of images using the prompt: “A photo of $S_∗$”. Our reconstruction score is then the average pair-wise CLIP-space cosine-similarity between the generated images and the images of the concept-specific training set.
- Second, we want to evaluate our ability to modify the concepts using textual prompts. To this end, we produce a set of images using prompts of varying difficulty and settings. These range from background modifications (“A photo of $S_∗$ on the moon”), to style changes (“An oil painting of $S_∗$”), and a compositional prompt (“Elmo holding a $S_∗$”).
Results
Limitations
While our method offers increased freedom, it may still struggle with learning precise shapes, instead incorporating the “semantic” essence of a concept. For artistic creations, this is often enough. In the future, we hope to achieve better control over the accuracy of the reconstructed concepts, enabling users to leverage our method for tasks that require greater precision.
Another limitation of our approach is in the lengthy optimization times. Using our setup, learning a single concept requires roughly two hours. These times could likely be shortened by training an encoder to directly map a set of images to their textual embedding. We aim to explore this line of work in the future.
References
[1]: Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel CohenOr. An image is worth one word: Personalizing text-toimage generation using textual inversion. arXiv preprint arXiv:2208.01618, 2022.
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
https://breynald.github.io/2024/09/25/An-Image-is-Worth-One-Word/