Learn Self-Adaptation Thinking through RL and switch thinking modes flexibly according to scenarios
Effective social intelligence simulation requires language agents to dynamically adjust the depth of reasoning, a capability conspicuously absent in current methods. Existing methods either lack such reasoning capabilities or enforce a uniform long-chain thinking reasoning in all scenarios, leading to excessive token usage and inappropriate social simulations. This paper proposes a Self-Adaptation Mindset Learning (AML) framework that strategically selects from four mindsets (intuitive reaction → deep thinking) based on real-time context. The core innovation of this framework, the Self-Adaptation Mindset Policy Optimization (AMPO) algorithm, achieves three breakthroughs compared to existing methods: (1) multi-granularity mindset design, (2) context-aware mindset switching in social interactions, and (3) token-efficient reasoning through deep self-adaptation. Extensive experiments on social intelligence tasks show that AML outperforms the current state-of-the-art method by 15.6%. Notably, while shortening the reasoning chain length by 32.8%, our method still outperforms GRPO by 7.0%. These results demonstrate that the context-sensitive mindset selection achieved by AMPO is closer to human self-adaptation thinking characteristics than the fixed-depth reasoning approach of GRPO.
ADAPTIVE MODE LEARNING FRAMEWORK
THINKING MODE
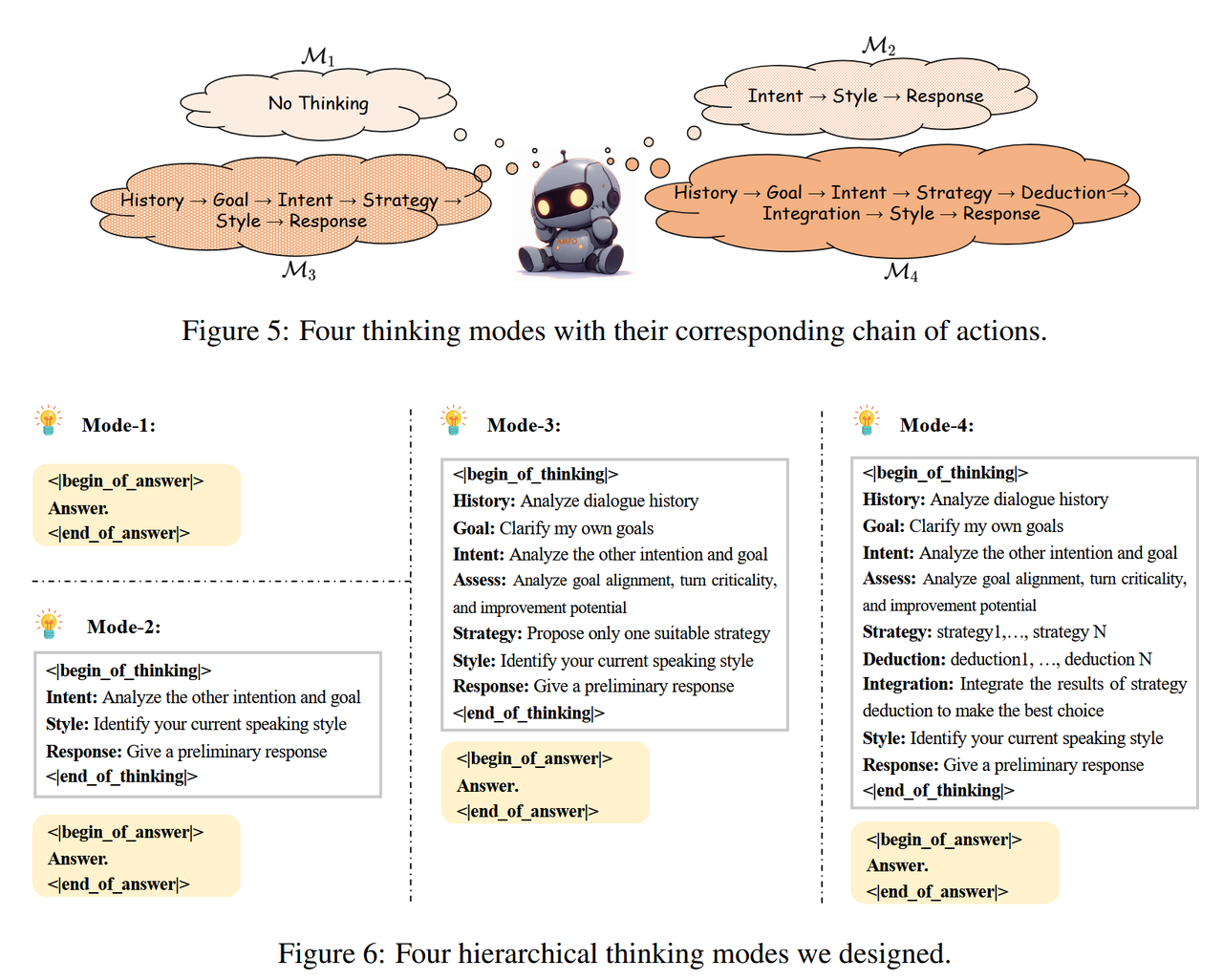
The Hierarchical Cognitive Control Theory (HCCT) (Koechlin & Summerfield, 2007; Badre, 2008) provides a theoretical framework for understanding human cognitive behavior. The theory posits that cognitive control operates through four distinct hierarchical levels, managing goals and behaviors with varying degrees of abstraction and time scales.
Inspired by the HCCT theory, this paper proposes a four-level thinking model for different dialogue scenarios, as shown in Figure 5 and Figure 6. The cognitive depth gradually progresses from intuitive reaction and shallow thinking to deep contemplation.
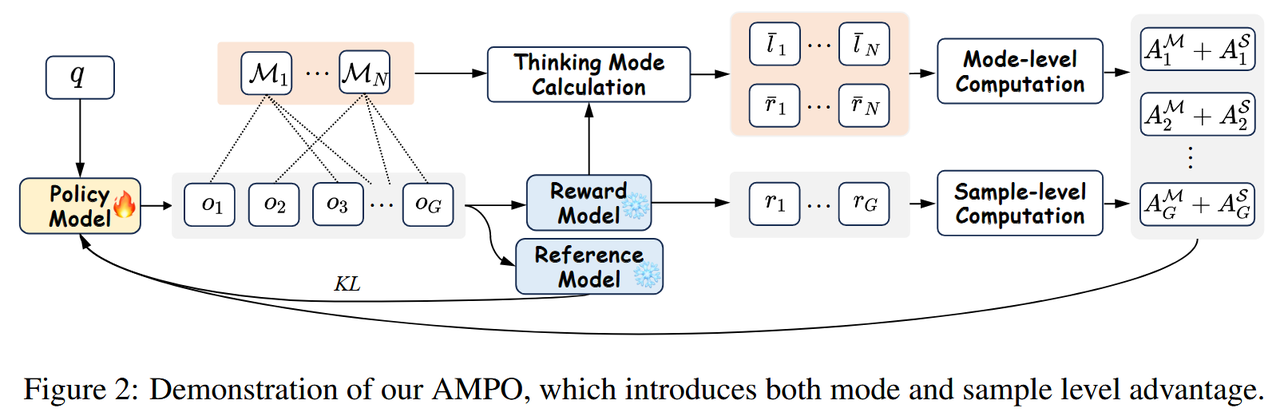
ADAPTIVE MODE POLICY OPTIMIZATION (AMPO)
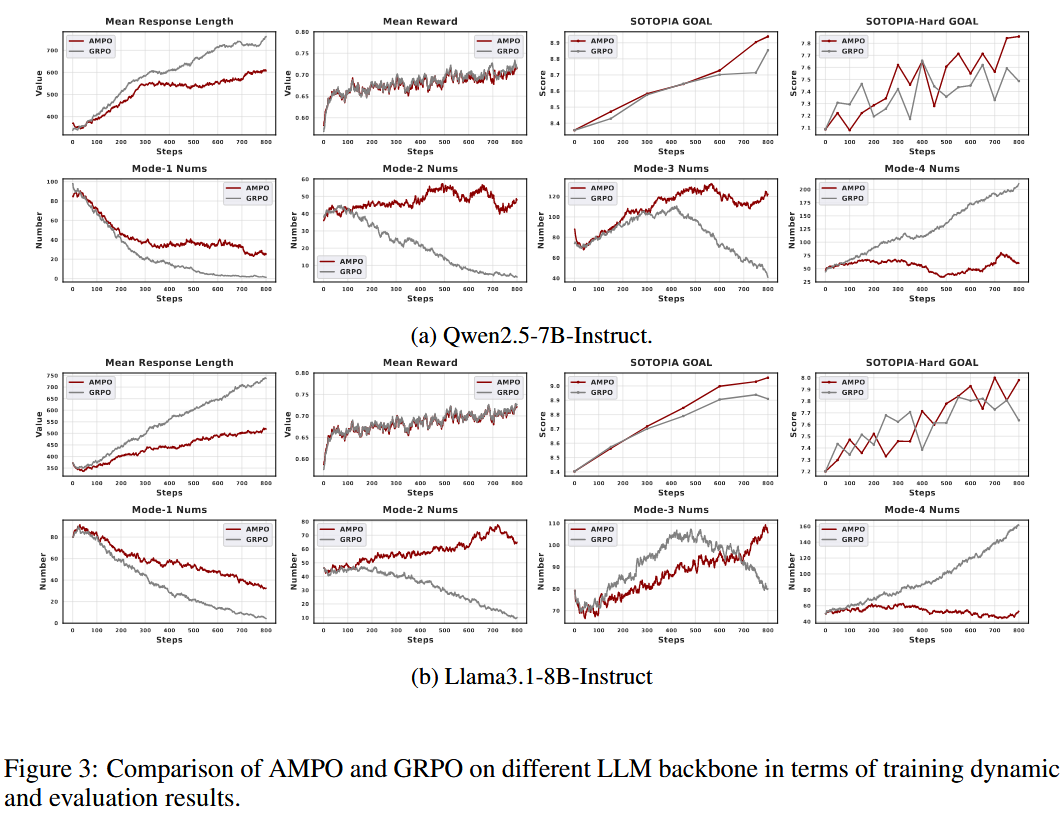
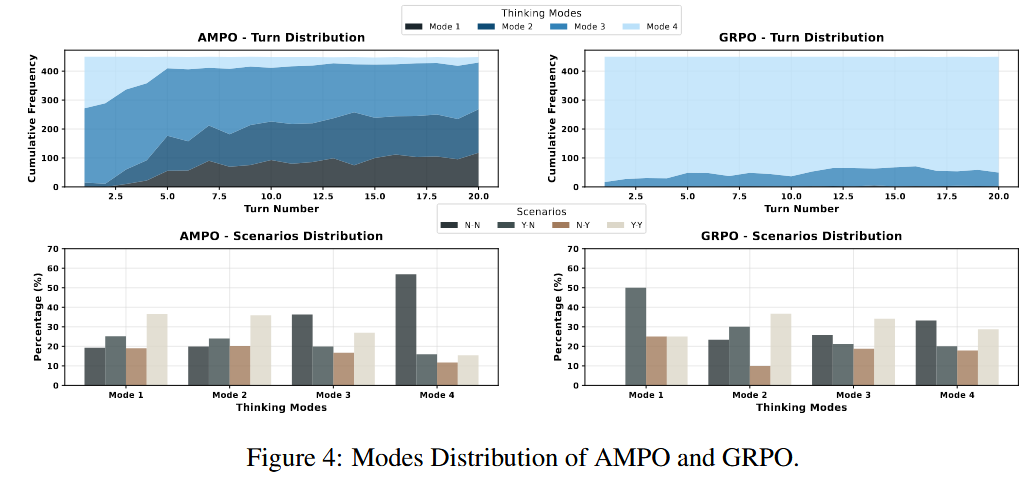
In the GRPO advantage calculation, each inference sample is treated as an independent thinking trajectory, which ignores the similarity of the inherent thinking patterns between trajectories and fails to learn information at the thinking mode level. This limitation will make it difficult for the model to dynamically adjust its thinking pattern according to the social situation, thus affecting its reasoning efficiency and effectiveness. Follow-up experiments also show that the GRPO-based reinforcement learning method tends to guide the model to converge to the most complex thinking trajectory, regardless of the specific situation.
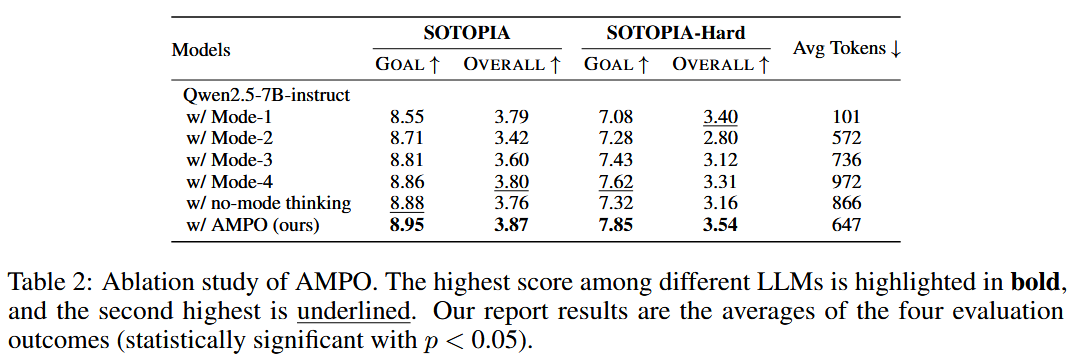
To this end, this paper proposes an Adaptive Mode Policy Optimization (AMPO) algorithm, which introduces both mode-level and sample-level information into the advantage estimation to promote self-adaptive thinking learning. By mastering the mode-level information, the model can learn to select the most appropriate mode; while through sample-level learning, the model can generate higher-quality action content within each mode.
- GRPO
- Sample-level advantages
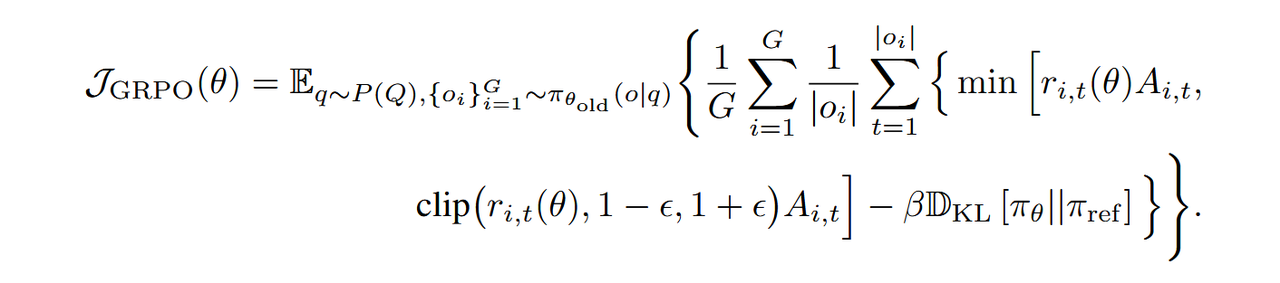
- AMPO
- Mode-level Advantages
- Sample-level advantages
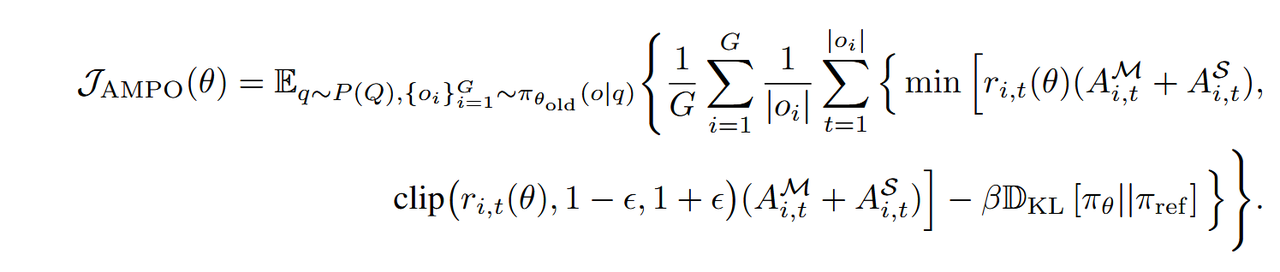
ADVANTAGE ESTIMATION
- The sample-level advantage is computed as follows:
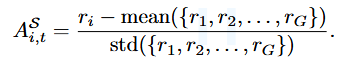
- The mode-level advantage is calculated as follows:
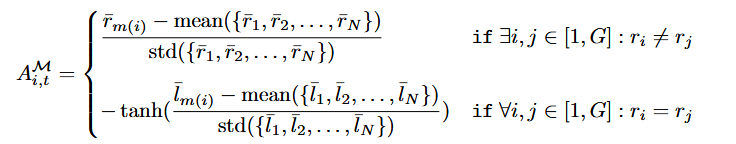
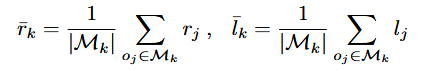
REWARDS
The design of the reward function is the key to reinforcement learning. The reward function in this paper consists of three components: answer reward $r_{i}^{a}$, format reward $r_{i}^{f}$, and answer length reward $r_{i}^{l}$. The reward $r_{i}$ is calculated as follows:

OPTIMIZATION PROCEDURE

EXPERIMENTS
- Main results:
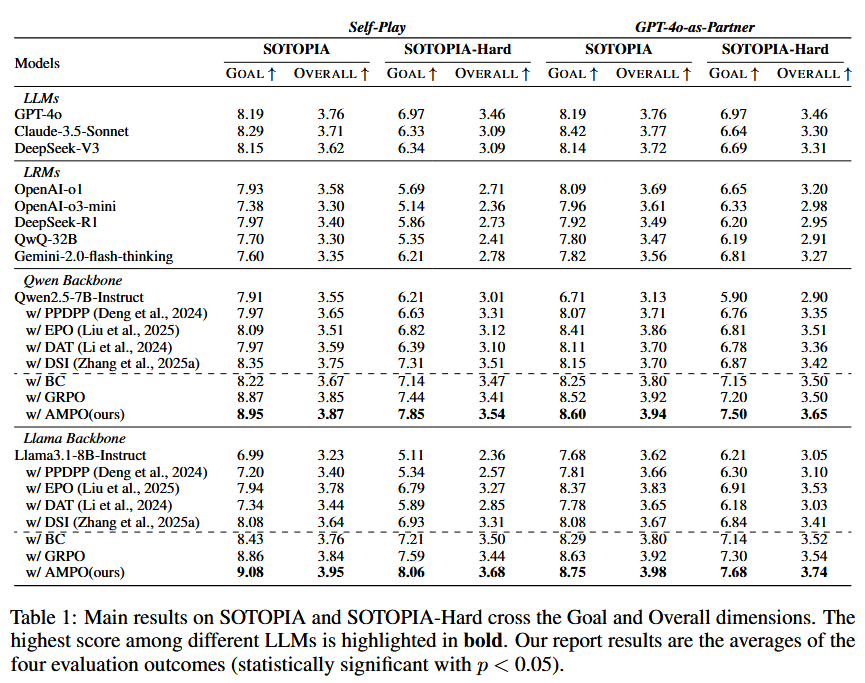
How AMPO benefits Adaptive Hybrid Thinking?
Learn Self-Adaptation Thinking through RL and switch thinking modes flexibly according to scenarios