GRPO: The Key Engine Driving DeepSeek's Exceptional Performance
1 | Paper: DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models |
In the fine-tuning process of large language models (LLM), reinforcement learning (RL) has become a key technology, especially the method of reinforcement learning (RLHF) through human feedback. In recent years, Group Relative Policy Optimization (GRPO) , as a new reinforcement learning algorithm, has gradually attracted widespread attention. This article will delve into the background, principles, and application of GRPO in LLM.
The background and origin of GRPO
In the application of language models, whether it is to let the model solve mathematical problems or to make it better meet human preferences in conversation (such as avoiding inappropriate output or providing more detailed explanations), we usually first lay the foundation for the model through large-scale unsupervised or self-supervised training. Then, through “Supervised Fine-Tuning” (SFT), the model can initially learn behaviors that meet specific needs. However, SFT often has difficulty explicitly integrating complex preferences of humans or high-level targets, such as requirements for answer quality, security, or diversity. At this point, “reinforcement learning fine-tuning” becomes a more powerful tool, which can directly optimize the output of the model through feedback signals, so that it better aligns with human expectations and target tasks.
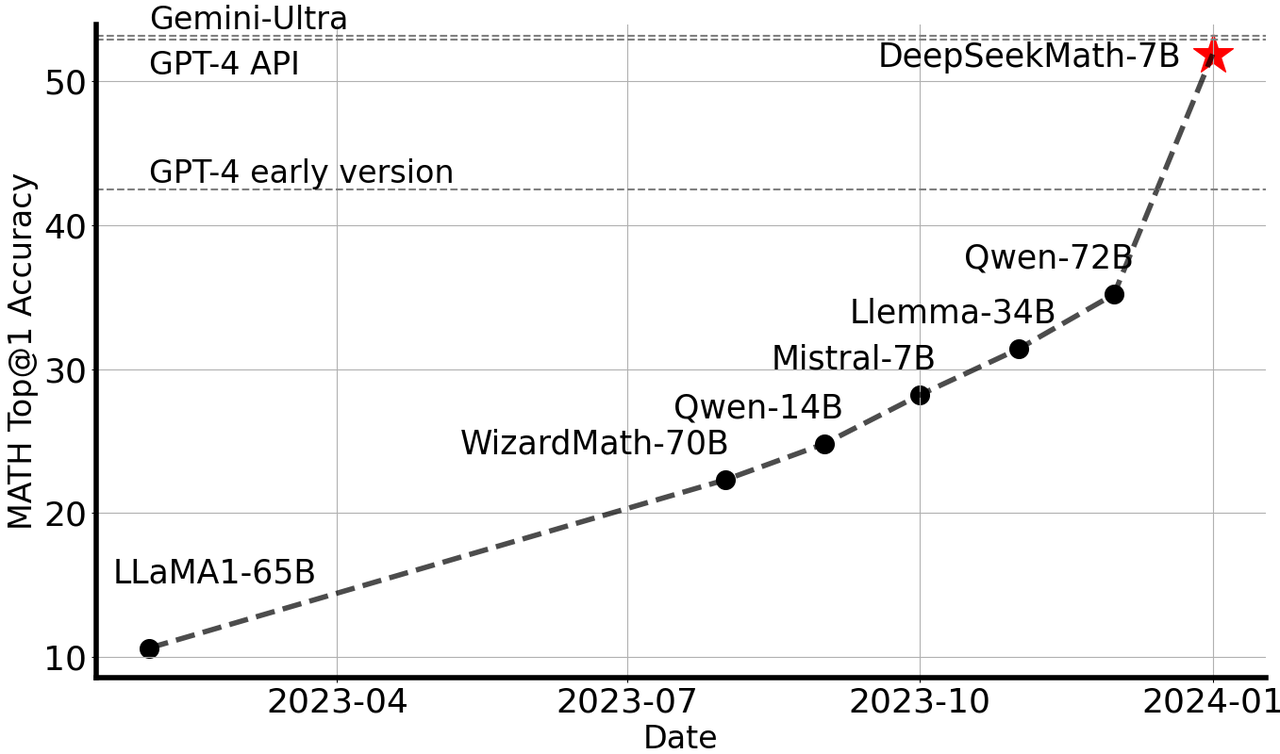
The GRPO algorithm was first proposed in the paper “DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models” by DeepSeek-AI, Tsinghua University, and Peking University in April 2024. It is an improvement on the Proximal Policy Optimization (PPO) algorithm. Since PPO was introduced by OpenAI in 2017, it has been popular in reinforcement learning tasks due to its stability and efficiency. However, with the expansion of model size and the increase of task complexity, the memory overhead and computational cost of PPO have become increasingly prominent, and GRPO emerged.
The core idea of GRPO
The core goal of GRPO is to simplify the algorithm structure, improve computational efficiency, and enhance the performance of the model in specific tasks (such as mathematical reasoning). Compared with PPO, GRPO has been optimized in the following aspects:
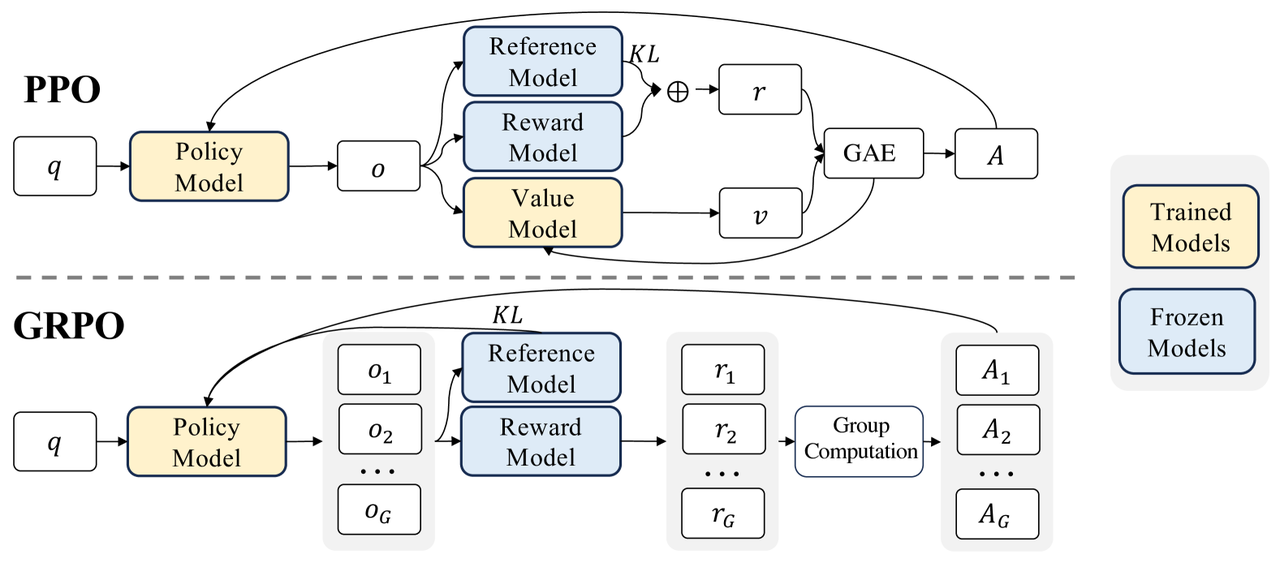
1. Group-Relative Reward
- Grouping Sampling: During training, samples (such as text sequences generated by the model) are divided into multiple groups in batches. For example, a batch may contain N samples, with each group containing M samples ((N = k\ times M)).
- In-group normalization: Standardize the sample reward values within each group (such as subtracting the mean or dividing by Standard Deviation), converting absolute reward values into relative reward values within the group . The purpose of this step is to reduce the impact of inconsistent reward dimensions in different tasks or training stages.
- Relative comparison: Through the relative comparison of samples within the group, it emphasizes that policy optimization should focus on the difference between good and bad samples within the same group, rather than the global absolute reward value. This is similar to the idea of “contrastive learning” in human preference learning.
2. Simplification of policy updates
- Omitting the advantage function: Traditional PPO relies on the advantage function to estimate the current action relative to the average performance, while GRPO directly replaces the advantage function through intra-group relative rewards, reducing computational complexity.
- Direct policy optimization: GRPO’s objective function directly updates the policy layer based on the relative rewards within the group, without limiting the update amplitude through complex clipping mechanisms like PPO.
3. Memory and Compute Optimization
- Reduce intermediate variable storage: PPO needs to store the probability distribution of the old policy (for importance sampling), while GRPO reduces the dependence of such intermediate variables through the intra-group comparison mechanism, thus reducing memory usage.
- Parallelized processing: Group partitioning makes computing parallelized, further improving training efficiency.
GRPO vs. PPO
The following compares GRPO and PPO from three aspects: algorithm design, training efficiency, and applicable scenarios.
| Feature | PPO | GRPO |
|---|---|---|
| Core mechanisms | Trust region optimization + importance sampling + shear mechanism | Intra-group relative reward + direct strategy optimization |
| Reward processing | Based on global Advantage function | Relative reward based on intra-group normalization |
| Memory consumption | High (need to store old policy data) | Low (group processing reduces intermediate variables) |
| Computational complexity | Higher (need to calculate advantage function and cut term) | Lower (simplifies target function, reduces extra computation) |
| Stability | Dependent on shear coefficient adjustment, easily affected by hyperparameters | The intra-group comparison is naturally stable, and the super-parameter robustness is stronger |
| Applicable scenarios | General reinforcement learning tasks (e.g. games, robots) | Fine-tuning of large-scale language models (such as mathematical reasoning and alignment) |
GRPO: Driving DeepSeek to Achieve Excellent Performance
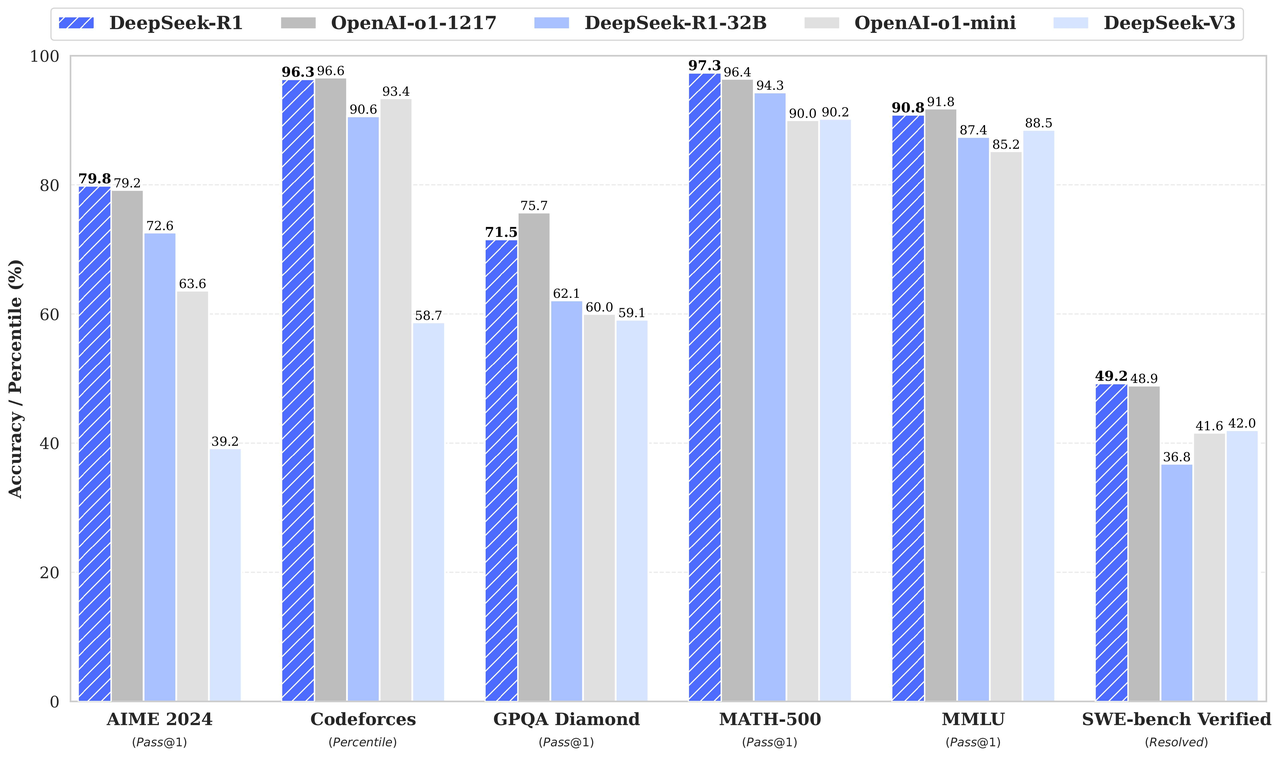
GRPO provides a powerful driving force for DeepSeek’s performance improvement by achieving efficient and scalable inference task training. The following are specific manifestations of how GRPO is transformed into actual success.
- Significantly improve reasoning ability:
GRPO helped DeepSeek-R1-Zero achieve a Pass@1 score of 71.0% in the AIME 2024 competition, further improving to 86.7% after a majority vote. This performance puts it on par with proprietary models such as OpenAI in solving mathematical and logical problems, demonstrating GRPO’s powerful optimization capabilities in complex inference tasks. - Inspire emerging capabilities:
Through the optimization of GRPO, DeepSeek models have developed advanced reasoning behaviors such as self-validation, reflection, and long-chain thinking. These abilities are crucial for solving complex tasks and further improve the performance of the model in practical applications. - Excellent scalability:
GRPO is an optimization mechanism based on the relative performance within the group, which eliminates the need for complex comment models and greatly reduces computational costs. This feature makes large-scale training possible, providing an efficient and economical solution for model expansion. - Efficient model distillation:
The smaller model distilled from the checkpoints trained by GRPO still retains high inference ability. This achievement not only makes AI technology easier to popularize, but also significantly reduces the cost of use, providing possibilities for a wider range of application scenarios.
By focusing on optimizing relative performance within the group, GRPO enables DeepSeek to continuously refresh performance standards in inference ability, long context understanding, and general AI tasks, while maintaining efficiency and scalability. This innovative algorithm not only lays the foundation for DeepSeek’s success, but also opens up new paths for the future development of AI technology.
Summary
GRPO summary has the following innovative points:
- Intra-group comparison mechanism: By grouping and intra-group standardization, the global optimization problem is transformed into a local comparison problem to improve training stability.
- Computational lightweight: omit advantage function and shear mechanism, reduce computational complexity and hyperparameter dependence.
- Alignment task optimization: Designed for language model alignment, it directly learns human preferences through intra-group comparison, reducing harmful output or erroneous reasoning.
As an emerging reinforcement learning algorithm, GRPO’s potential is not limited to mathematical reasoning tasks. With further research, GRPO is expected to demonstrate its advantages in more complex tasks, such as Natural-language Understanding, dialogue generation, and other fields. In addition, its efficient computational characteristics also provide new possibilities for applying RLHF in resource-constrained environments.
The introduction of GRPO has injected new vitality into the development of reinforcement learning algorithms. It not only solves the limitations of PPO in computing resources and memory consumption, but also provides a more efficient solution for LLM fine-tuning and alignment. In the future, with the continuous evolution of technology, GRPO is expected to shine in more fields.
GRPO: The Key Engine Driving DeepSeek's Exceptional Performance