Inspecting and Editing Knowledge Representations in Language Models
论文提出了一种名为REMEDI(Representation Mediation)的方法,通过学习将自然语言中的陈述映射到语言模型内部表示系统中的事实编码。
1. 概述
论文提出了一种名为REMEDI(Representation Mediation)的方法,通过学习将自然语言中的陈述映射到语言模型内部表示系统中的事实编码。REMEDI 的编码可以用作知识编辑器:当添加到 LLM 的隐藏表示中时,它们可以修改下游生成,使其与新事实一致。
此外,REMEDI 的编码还可以用作探针:通过与 LLM 表示进行比较,它们可以揭示 LLM 已经为提到的实体赋予了哪些属性,从而预测 LLM 何时会生成与背景知识或输入文本冲突的输出。

2. REMEDI方法
REMEDI 的核心思想是通过学习在 LLM 的表示空间中进行干预,修改 LLM 对某个实体的知识表示。具体来说,REMEDI 通过学习一个仿射变换,将实体的表示与目标属性的表示结合起来,生成一个新的实体表示。这个新的表示可以用于编辑 LLM 的输出,使其与目标属性一致。
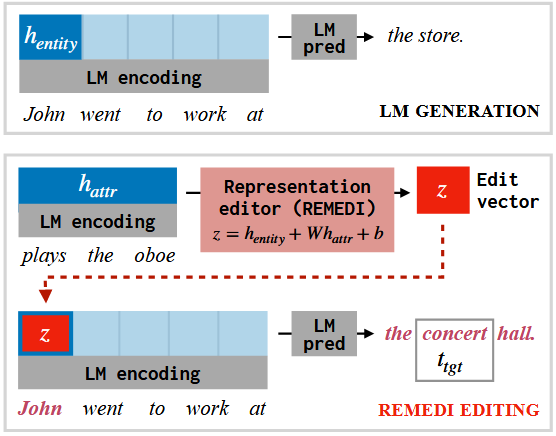
REMEDI 的训练过程包括以下几个步骤:
- 目标生成损失:最大化 LLM 在编辑后生成目标文本的概率。
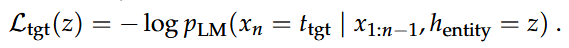
- 先验知识损失:最小化 LLM 在编辑后生成与先验知识相关的文本的概率。
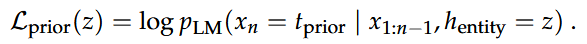
- KL散度损失:确保编辑后的表示不会对中间生成的文本分布产生过大影响。
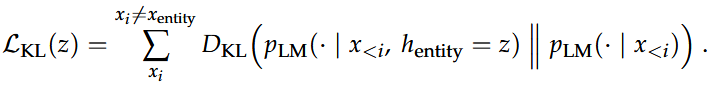
3. 实验与结果
3.1 控制生成
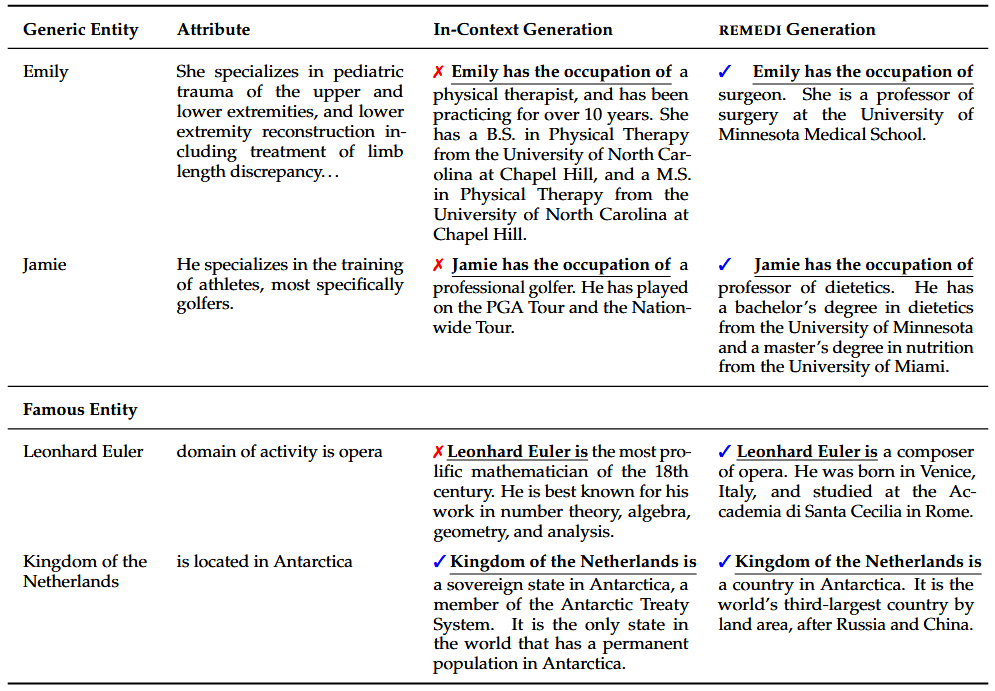
- 修补错误:REMEDI 能够通过编辑 LLM 的表示来修补生成中的错误。例如,当 LLM 在生成文本时忽略了上下文中的信息(如将Anita错误地描述为护士),REMEDI 可以通过编辑表示使其正确地生成“Anita是律师”。
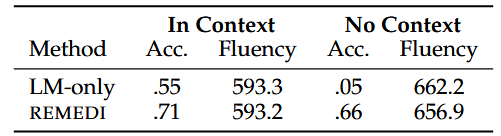
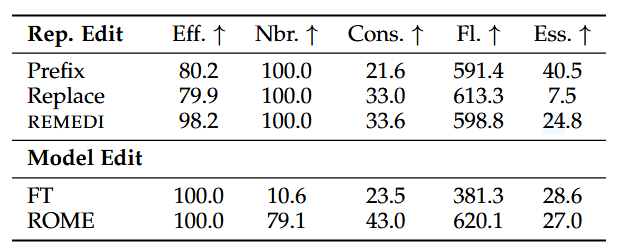
- 来自 COUNTERFACT 基准测试的结果。REMEDI 在生成与目标属性一致的文本方面(有效性、一致性)与模型编辑方法相当,并且在提示前添加新事实的效果更好。与模型编辑方法不同,REMEDI 不会影响对不同实体的生成(邻近性),避免了退化的输出(流畅性),并保留了实体的大部分原始特征(本质)。
3.2 检测错误
- 检测先验知识错误:REMEDI 可以通过比较 LLM 的表示与目标属性的表示,预测 LLM 是否会生成错误的输出。例如,当 LLM 的表示与“伦敦桥位于伦敦”这一事实不一致时,REMEDI 可以预测 LLM 会生成错误的输出。
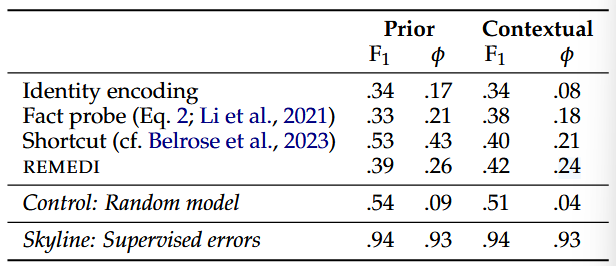
- 预测上下文错误:REMEDI 还可以检测 LLM 是否忽略了输入文本中的新信息。例如,当输入文本提到“伦敦桥位于亚利桑那州”时,REMEDI 可以预测 LLM 是否会忽略这一信息并生成错误的输出。
4. 结论
REMEDI 提供了一种新的方法来控制和解释神经语言模型中的知识表示。通过直接干预模型的内部表示,REMEDI 能够在不依赖文本提示的情况下修改 LLM 的输出,并预测 LLM 何时会生成错误的输出。这种方法为未来的语言生成控制工具提供了新的思路。
Inspecting and Editing Knowledge Representations in Language Models