LLM 知识编辑调研
大语言模型(LMMs)惊人的知识保留能力,归功于 LLMs 处理和压缩大量数据的方式,可能形成了更简洁、连贯且可解释的生成过程模型,本质上是创建了一种“世界模型”。
语言能力与知识存储的分离
为了深入理解 LLMs 中智能涌现的内在机制,[1] 以大脑定位为原型进行了类比研究,有以下结论:
- 在模型上表现为语言能力与知识之间的分离;
- 负责语言处理的核心区域仅占模型参数的约 1%。
- 语言功能参数的无效更改可能会严重损害模型的语言能力(LLaMA-13B 中,仅改变一个参数就可能对其语言能力造成显著损害);
- 语言能力的提高并不一定意味着知识水平的提升;
- 大型语言模型中存在一个独立于语言处理的知识存储区域(FFN / 多层感知器 (MLP))。
知识编辑技术
由于 LLMs 存在一些局限性,如事实错误、可能生成有害内容以及由于训练截止日期导致的知识过时。重新训练以纠正这些问题既昂贵又耗时。
知识编辑技术能够以较低的成本对模型进行事后修改,且该技术专注于特定区域的调整,而不会影响整体性能。
背景介绍
大语言模型中的知识存储机制
Transformer 之所以表现出色,部分原因在于其参数中存储了丰富的信息,包括语言、常识、算术和世界知识等。然而,这些知识在 LLMs 中的具体组织方式仍然是一个谜。当前的研究致力于揭示 LLMs 行为的机制,特别是知识存储的复杂性。
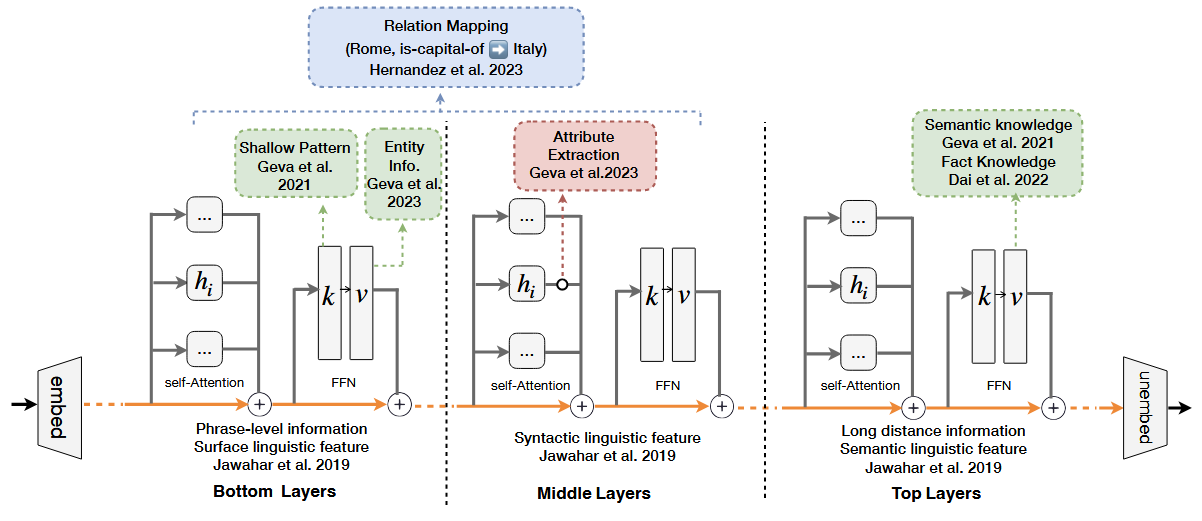
一个关键的研究方向是确定知识在模型中的具体位置。如图 1 所示:
Jawahar 等人 [2] 发现 BERT 模型在较低层主要捕捉短语级信息,在中间层编码语言元素的复杂层次结构,而在最上层则集中体现语义特征。
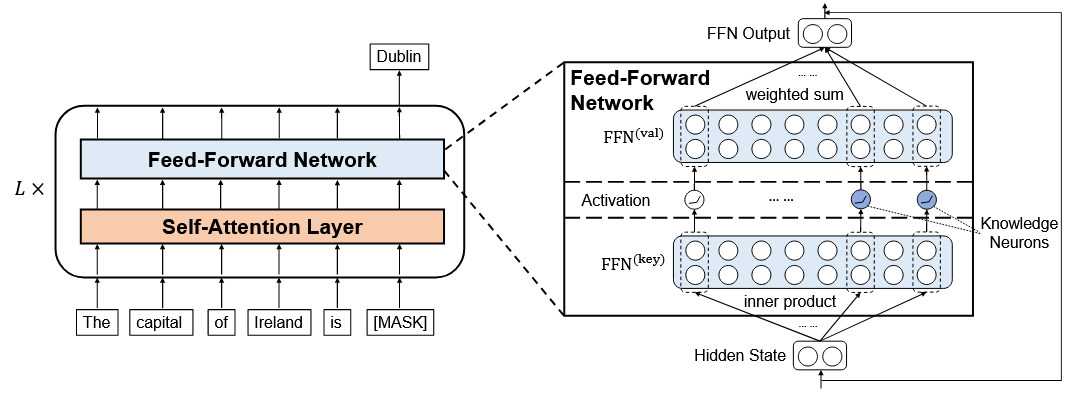
Geva 等人 [3] 提出,Transformer 中的前馈神经网络(FFN)层类似于键值记忆系统,输入作为查询,第一层表示键,第二层表示值,最终输出是激活值的加权和。
Dai 等人 [4] 进一步提出“知识神经元”的概念,认为知识集中在语言模型最上层的少数 FFN 神经元中。
……
尽管这些研究揭示了 LLMs 中知识存储的某些方面,但如何检索和利用这些知识仍然是一个问题。
相关技术
参数高效微调
微调 LLMs 的所有参数可能在计算上非常昂贵。为了实现高效适应,参数高效微调(PET)技术被提出,旨在匹配全参数微调的性能,同时仅更新最少的参数。典型方法有:Adapter、LoRA。
然而,PET 通常用于提升任务性能,而非专门用于知识编辑。现有 PET 方法在知识编辑方面的有效性在很大程度上尚未得到探索。
知识增强
知识增强方法是解决 LLMs 中缺失或错误信息的一个很好的解决方案,其中最流行的方法是检索增强方法(Retrieval-Augmented)。
但它仍然存在一些缺点,包括检索到的数据通常包含一些噪音,例如与问题无关但可能与另一个问题相关的内容(即不一定是随机噪音)。
持续学习
持续学习(Continual Learning, CL),也称为终身机器学习或增量学习,目标是使机器学习模型能够随着时间的推移学习新任务并适应新领域,而不会忘记早期的任务,这与知识编辑的目标相似。
相比之下,知识编辑则专注于操纵和更新预训练语言模型内部学习到的知识表示,而不考虑底层任务或领域。
知识编辑的目标是动态优化语言理解,独立于最终应用,解决预训练语言模型在部署后的“固定性”问题。
机器遗忘
此外,模型必须具备摒弃不良(错误)行为的能力,这与机器遗忘的概念一致。例如 EUL [5] 是一种高效的遗忘框架,可以在数据移除后高效更新 LLMs,而无需重新训练整个模型。
然而,知识编辑不仅限于遗忘,它还包括主动修正或删除模型已学习的知识库。
总结
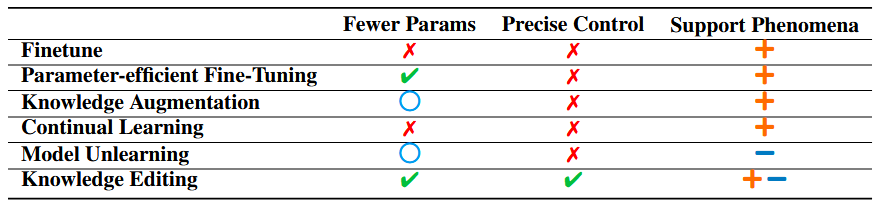
如表 1 所示,知识编辑与简单应用现有方法不同,知识编辑需要对 LLMs 的运作方式有更深入的理解。它不仅涉及将已知技术应用于新模型,还关乎理解和操纵 LLMs 中细致入微的知识存储和处理能力。此外,知识编辑代表了一种更精确和细粒度的模型操纵形式,因为它涉及选择性地改变或增强模型知识库的特定方面,而不是对整个模型进行广泛的重新训练或微调。这些特性使得知识编辑成为更新和优化 LLMs 以应对特定任务或应用的潜在更高效和有效的方式。
知识编辑
任务定义
知识编辑的初始目标是修改 LLM 中的特定知识 $k$,并在不微调整个模型的情况下提高 LLM 的一致性和性能。这些知识可以涉及许多领域和类型,例如事实、常识、情感等。
假设原始模型为 $\theta$,给定要修改的知识 $k$,通过知识编辑过程 $F$,我们将得到编辑后的模型 $\theta’$:
$$
\theta’ = F(\theta, k) \tag{1}
$$
编辑后的模型 $\theta’$ 应覆盖模型对知识 $k$ 的不良输出,并保持其他知识不变:
$$
\theta’(k) \neq \theta(k) \tag{2}
$$
$$
\forall k’ \neq k, \quad \theta’(k’) = \theta(k’) \tag{3}
$$
作为一个知识库,知识编辑必须满足三个基本设置:知识插入、知识修改和知识擦除。
知识插入
知识插入通过赋予 LLMs 先前不在其知识库范围内的新知识来使其吸收新兴信息:
$$
\theta’ = F\left(\theta, {\emptyset} \to {k}\right)
\tag{4}
$$
知识修改
知识修改指的是改变已经存储在 LLM 中的知识:
$$
θ’= F (θ, {k} → {k’}) \tag{5}
$$
可以分为两类:
- 知识修正:旨在纠正嵌入在 LLM 中的不准确之处,以确保提供准确的信息。
- 知识干扰:修改 LLM 以回答反事实的或错误的提示。
知识擦除
知识擦除旨在删除或消除模型中预先存在的知识,主要用于重置特定的事实、关系或属性:
$$
θ’ = F (θ, {k} → {\emptyset}) \tag{6}
$$
实施知识擦除对于消除偏见和有害知识、减少对机密或私人数据的回忆至关重要,从而促进负责任和值得信赖的人工智能。
方法
LLM 的发展已达到其能力与人类认知过程极为相似的程度,尤其是在学习和获取知识方面。借鉴人类学习的方式,我们可以将这些概念类比应用于编辑 LLM 的过程,如图 2 所示。
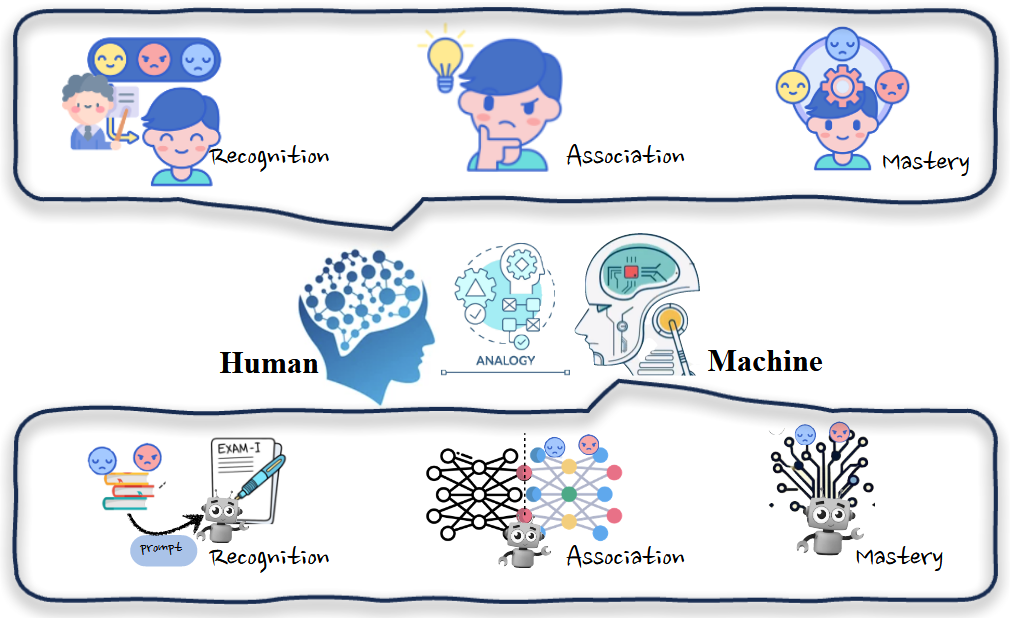
识别阶段:在识别阶段,模型需要在一个相关的上下文中接触到新知识,就像人们初次遇到新信息一样。例如,提供新的事实说明的句子作为模型的演示,使模型初步识别需要进行编辑的知识。
关联阶段:在关联阶段,新知识与模型中的现有知识之间形成联系,类似于人类将新想法与已有概念相关联。方法会将输出或中间输出 $h$ 与学习的知识表示 $h_{know}$ 结合或替换。
掌握阶段:掌握阶段涉及模型完全获取其参数中的知识并可靠地利用这些知识,类似于人类的深度掌握。该方法直接改变了模型的权重 $∆W$,模型可以在没有任何外部帮助或合并的情况下处理问题。
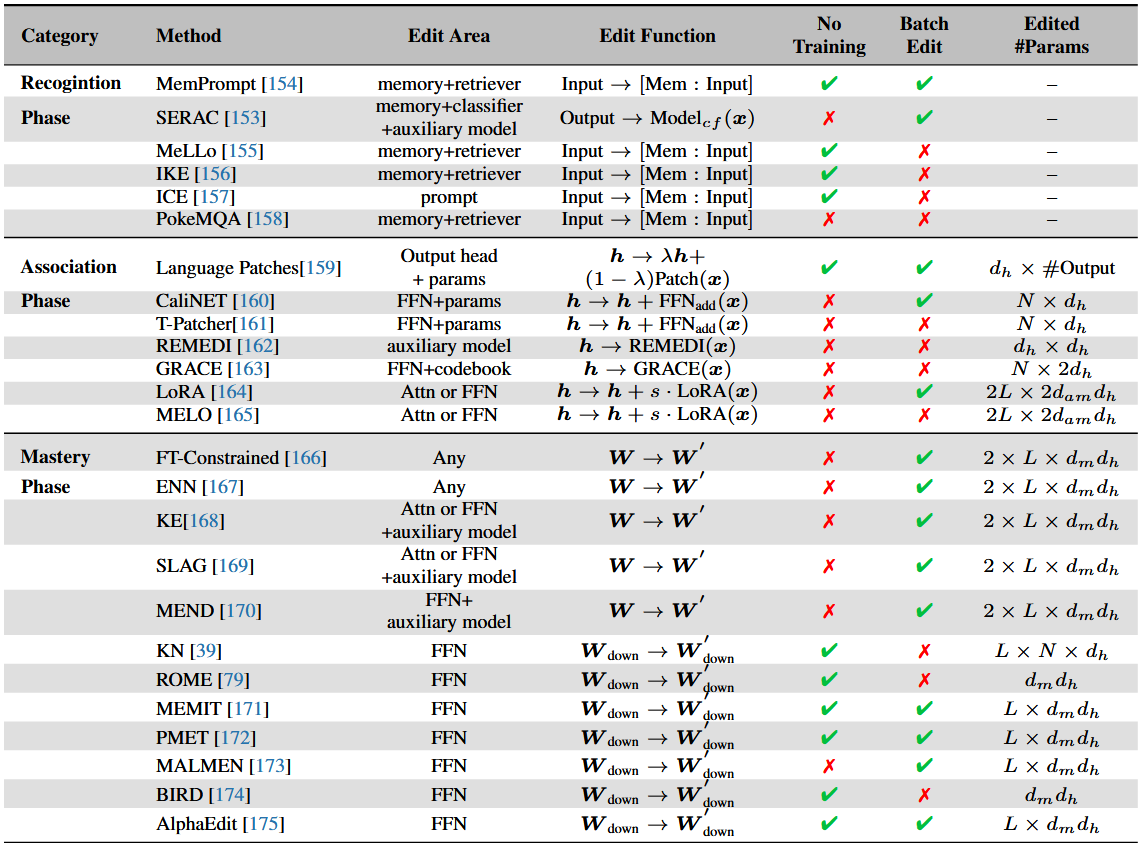
表2 LLM 知识编辑代表性方法的比较。
No Training:不需要额外训练的方法;
Batch Edit:方法是否支持在一个过程中同时编辑多个案例;
Edit Area:模型组件被使用的位置;
Editor #Params:编辑时需要更新的参数;
$L$:需要更新的层数;
$d_h$:Transformer 中隐藏层的维度;
$d_m$:上投影和下投影之间存在的中间维度;
$N$:每层中需要更新的神经元总数。
识别阶段:借助外部知识
In-context Knowledge Editing (IKE) [6] 通过构建三种类型的演示——复制、更新和保留——来帮助模型进行可靠的事实编辑。
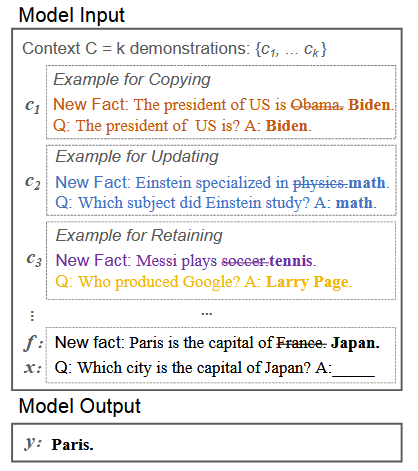
图3 IEK示例。 虽然当前的知识编辑方法能够准确回忆已编辑的事实,但在构建的多跳问题上却表现糟糕。MeLLo [6] 将问题分解为不同的子问题以处理多跳问题,并从记忆中检索每个子问题的更新事实。
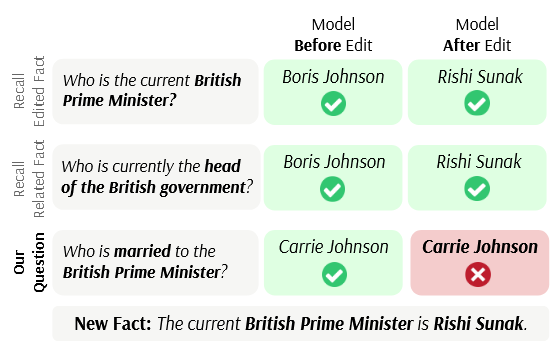
图4 现有的知识编辑方法通常在回答编辑事实的改写问题时表现良好,但在涉及编辑事实的多跳问题时表现不佳。
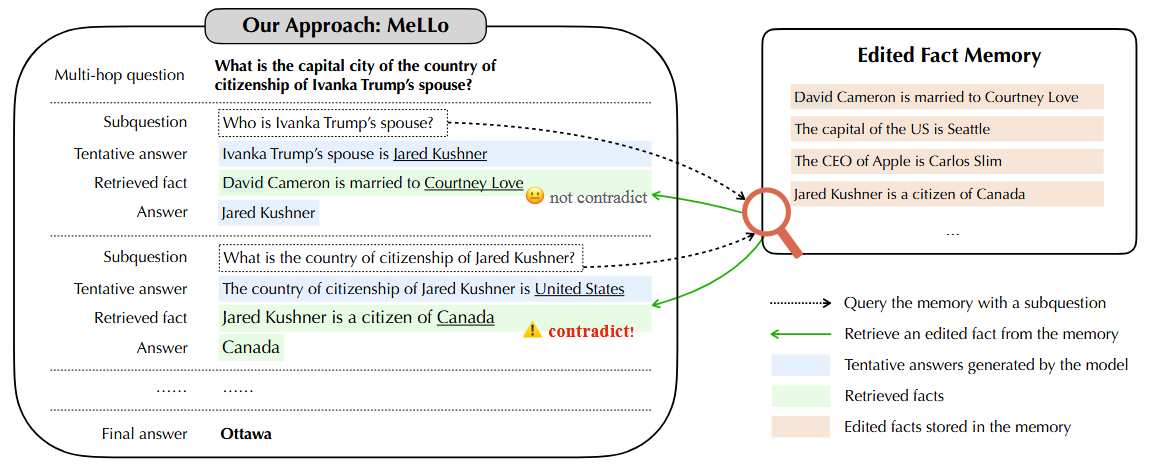
关联阶段:将知识融入模型
与识别阶段不同,这种方法学习新知识 $h_{Know}$ 的表示,并将该信息与原始模型的表示 $h$ 合并:
$$
h_{final} = h + h_{know} \tag{7}
$$
- Murty 等人 [7] 受先前研究发现 FFN 可能存储知识的启发,向 FFN 添加神经元,编辑后的输出是原 FFN 输出与新添加知识的组合。
$$
FFN’(x) = FFN(x) + △FFN(x) \tag{8}
$$
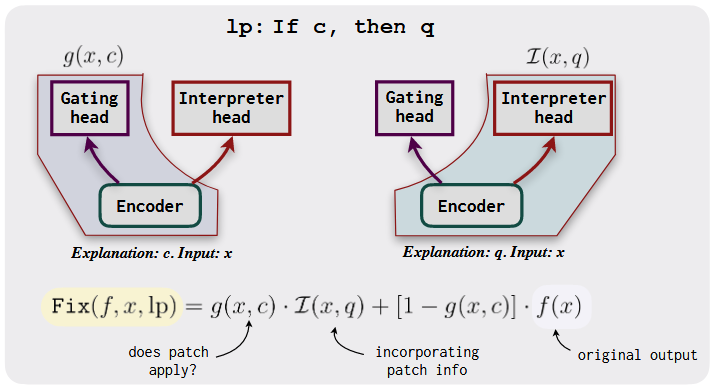
- T-Patcher [8] 为每个输出误差添加一个神经元。
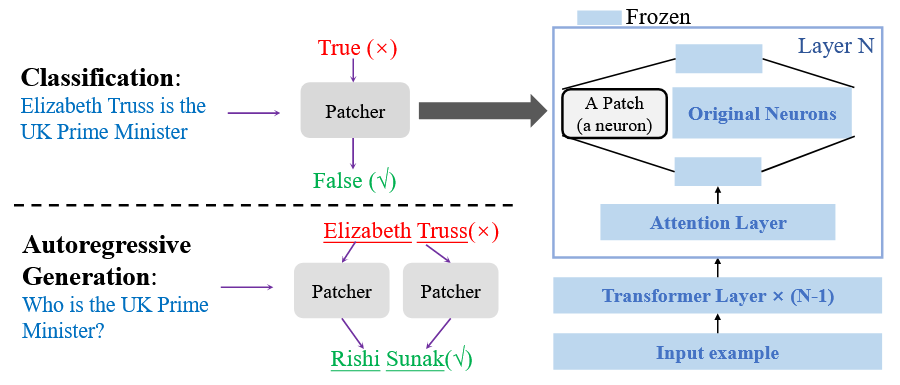
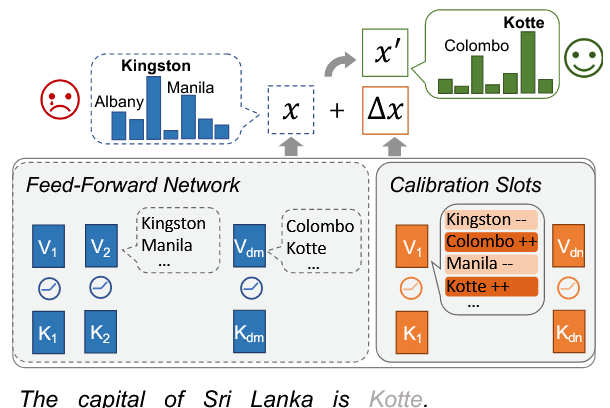
- CaliNet [9] 则向校准记忆插槽的神经元添加知识。
- 与向模型添加参数不同,REMEDI [10] 通过将属性向量合并到其原始模型的表示中,直接替换了实体的表示。
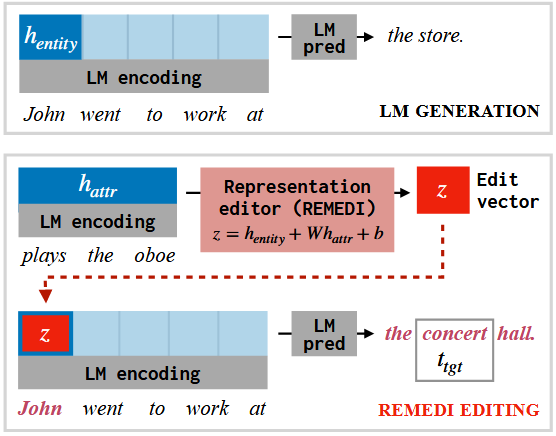
图9 REMEDI 的示例。给定一个提示(John went to work at)和一个期望属性(plays the oboe),REMEDI 对 John 的隐藏表示进行编辑,以增加适当补全(the concert hall)的概率。
掌握阶段:编辑内在知识
微调模型是更新知识的直接方法;然而,训练整个模型需要大量的计算资源并且非常耗时。与此同时,微调技术通常会出现灾难性遗忘和过拟合问题。
元学习
为了克服这些缺点,一些元学习方法被提出来编辑模型。这类方法不是直接更新权重,而是训练一个超网络学习模型的权重变化 $∆W$。
$∆W$ 与模型权重维度相同:KE [11] 直接使用新知识的表示来训练模型以更新矩阵。SLAG [12] 引入了一个新的训练目标,考虑了顺序、局部和泛化的模型更新。
MEND [13] 应用秩一分解将模型分为两个秩一矩阵,从而可以计算 $∆W$,显著减少了参数数量。
尽管这些方法展现出一定的结果,但它们在多任务编辑上表现不佳,因为它们忽略了这些编辑之间的冲突。
- Han 等人 [14] 提出了一种新颖的框架,通过并行编辑器来分而治之地处理编辑。具体来说,他们设计了显式多重编辑器 MoEditor 和隐式多重编辑器 ProEditor,分别从动态结构和动态参数的角度学习多样化的编辑策略,从而能够以高效的端到端方式解决冲突数据。
- MALMEN [15] 通过将参数偏移聚合表述为最小二乘问题来改进 MEND,并支持同时进行大规模编辑。
定位-编辑
部分工作通过首先定位知识存储的位置,然后对特定区域进行编辑来实现知识编辑。
- 知识神经元 [16] 这篇文章提出了一种通过计算梯度变化的敏感性来进行知识归属定位的方法。随后,他们直接使用目标知识的嵌入来修改相应的值槽。
ROME [17] 和 MEMIT [18] 采用因果分析方法来检测隐藏状态中哪一部分更为重要。他们将编辑视为最小化优化问题,并对权重进行编辑。
尽管编辑 FFN 区域比较有效,PMET [19] 也通过注意力头进行编辑,并展示了更好的性能。
为了更有效地解决 LLMs 中原有知识被破坏的问题,AlphaEdit [20] 提出在将扰动应用于模型参数之前,将其投影到保存知识的零空间中,从而显著减少这一问题。
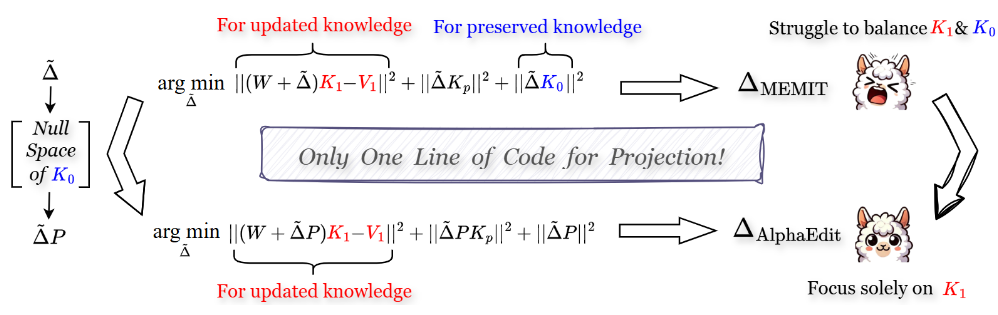
图11 AlphaEdit 与当前方法的范式对比。
总结
这些方法直接编辑模型的参数,为改变其行为提供了更持久的解决方案。这些更改被嵌入到模型的结构中,因此即使用户可以访问模型的权重,也无法绕过这些更改。这确保了持久且可靠的修改。然而,由于 LLMs 的机制尚不明确,副作用无法控制。一些研究人员对此类方法持怀疑态度,因此这仍是一个不成熟的研究领域,需要进一步探讨。
评估
数据集
KnowEdit [21] 合并了几个现有的知识编辑数据集。

此外还有一些知识编辑任务相关的数据集:
- DepEdit
- Eval-KLLM
- Bi-ZsRE
- MzsRE
- Entity Inferences
- TempLAMA
- Atoken
- MEMITcsk
- RaKE
- Dune
指标
知识编辑旨在根据修改后的事实改变模型行为。然而,知识是相互关联的;改变一个事实可能会以复杂的方式波及并影响其他事实。这种相互依赖性使得评估编辑效果变得困难。因此先前工作中的关键评估标准总结为四类:编辑成功性、可移植性、局部性和流畅性。
编辑成功
编辑的目的是改变模型对给定知识的输出。先前的工作采用了两个指标,即可靠性和泛化性。因此,编辑成功意味着编辑后的模型不仅应正确回答问题本身,还应为具有相似表达的输入提供正确答案。
- 可靠性:目标是评估编辑后的模型是否能够为给定上下文提供目标答案。
- 泛化性:旨在评估编辑后的模型在改写上下文中的表现。
可移植性
当知识被修正时,模型应当能够推理出修正对下游的影响。可移植性包含三个不同的部分:
- 别名:一个主题的编辑不应与其表达方式有所不同。
- 组合性与推理:这要求后编辑模型能够根据更改的事实进行推理。例如,当我们将美国总统从唐纳德·特朗普更改为乔·拜登时,问题“美国第一夫人是谁?”的答案也应相应更改。
- 逻辑泛化:这些变化与修改的事实语义相关,并且预期会因编辑而改变。例如当 $(s, r, o)$ 的事实发生变化时,知识的反向关系 $(o, \hat{r}, s)$ 也应随之改变。
局部性
在编辑知识时,我们可能会无意中改变我们不希望修改的知识。良好的编辑应当在不影响无关知识的情况下修改知识的局部性。局部性的评估包括两个层面:
- 分布内:这包括来自同一分布的知识。如之前的研究所示,过度编辑是一个常见现象。关系特异性原则认为,先前更新的主体的任何其他属性在编辑过程后应保持不变。
- 分布外:与目标知识无关的其他知识不应受到影响。也就是说,我们也不希望编辑后的模型失去处理其他任务的通用能力。
一些研究使用特异性(Specificity)来表示局部性(locality)。
生成能力
先前的研究发现,在编辑模型后,某些模型倾向于生成重复的内容,并且每当遇到主题词时,往往会生成编辑目标。此外,使用流畅性指标来评估编辑后模型的生成能力。
分析
不同知识编辑方法的比较
在本节中,我们关注涉及模型内部参数调整的方法,特别是 MEND、ROME、MEMIT 和 FT-L。由于这些方法修改了模型的参数,一个根本性问题随之而来:是什么使得某些知识编辑方法(如MEND)在局部性和整体表现上更为优越?
我们将变化表示为 $W′ = W + ∆W_{edit}$,其中 $W$ 是原始权重,$∆W_{edit}$ 表示编辑过程中所做的修改。因此,本节的主要重点是辨别不同编辑方法的矩阵 $∆W_{edit}$ 之间的差异。
稀疏性
知识编辑的目的是修改模型中的特定知识,这表明一个直观的假设,即 $∆W$ 矩阵很可能是稀疏的。图 12 捕捉了知识编辑引起的权重更新的可视化结果。
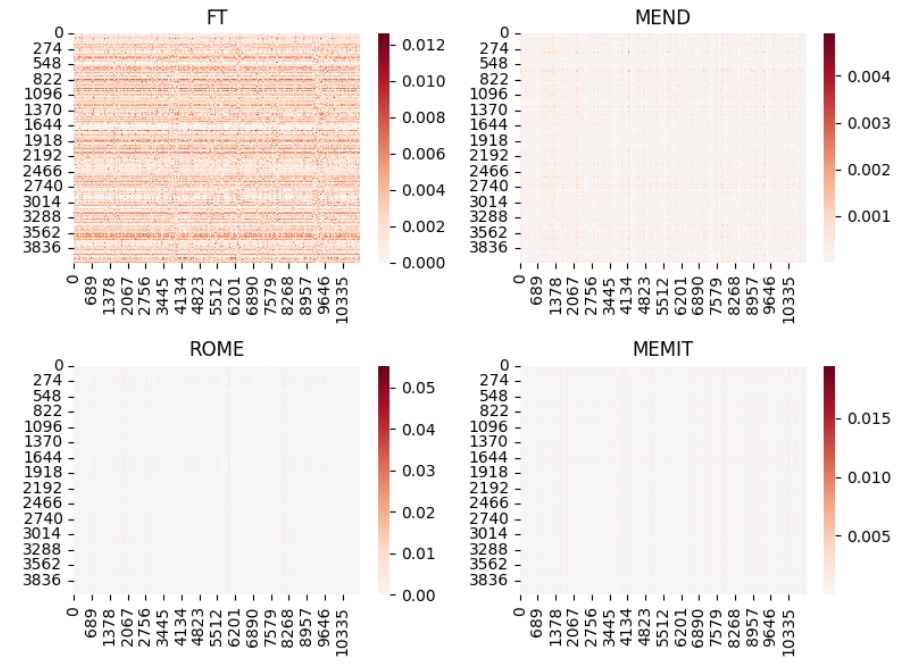
在 MEND 方法中,所训练的超网络可以被视为一种工具或“探针”,帮助我们探索和理解模型用于编码知识的内部机制,从而提供关于模型如何表示和处理信息的见解。
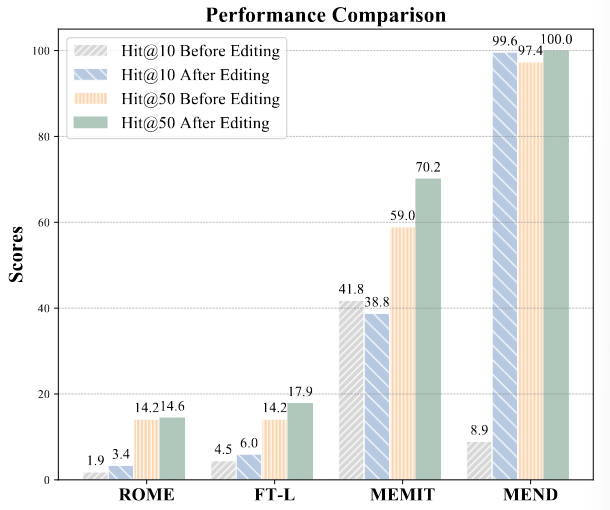
映射到嵌入空间
为了进一步研究不同编辑方法之间的差异,将 LLM 的权重映射到词汇空间来分析 Transformer 的参数,并发现嵌入空间可以解释这些权重。选择更新值矩阵 $∆W$ 的前五列,并将 $W’$ 和 $W$ 的对应列映射到嵌入矩阵 $E$ 中,以在词汇空间中获取logits。然后计算新知识在输出 logits 中的 Hit@10 和 Hit@50。
如图 13 所示,在编辑过程后,MEND 的 Hit@10 分数显著提高,这意味着 MEND 可能能够找到并更改存储目标知识的正确神经元,而无需进行完整的知识定位分析。
知识定位分析
如图 14 所示,以实体 SMAP 为例,对其进行因果分析:
- [SMAP 创建于 → 日本]
然后,考虑一个与事实相关的问题:
- [SMAP 创建于 → 日本;语言 → 日语]
最后,采用一个不相关的事实与问题结合:
- [SMAP 类型 → 开创性团体]
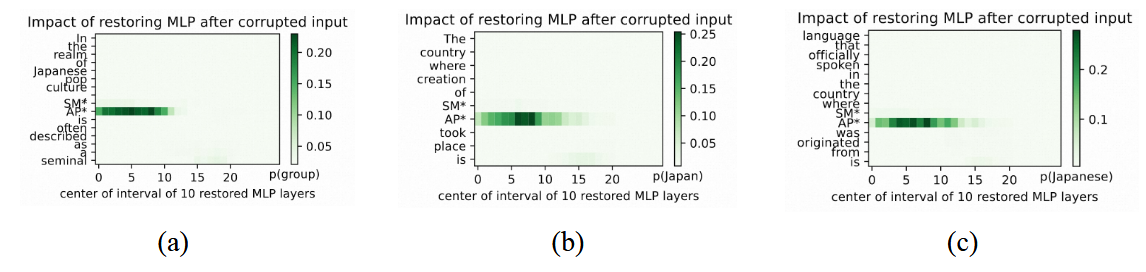
然而,正如 Ju 和 Zhang [21] 所提到的,特定知识及其相关知识链的定位结果应表现出比无关知识更大的相似性。目前,因果分析方法似乎只能定位与实体本身相关的区域,而非整个事实。模型是通过从预训练语料库中记忆的答案进行作弊,还是通过多步推理机制来执行这些答案,仍不明确。解开这些知识架构对于通过知识编辑等方法实现更精确和稳健的模型干预至关重要,但目前仅操纵MLP权重是不够的。
大语言模型中的隐式知识结构
理解 LLM 中的知识结构对于有效的知识编辑至关重要。先前的研究通常将 LLM 中的知识概念化为类似于知识图谱(KG)中的三元组,包括主体、关系和客体。这种类比虽然有用,但简化了 LLM 中知识表示的复杂性。
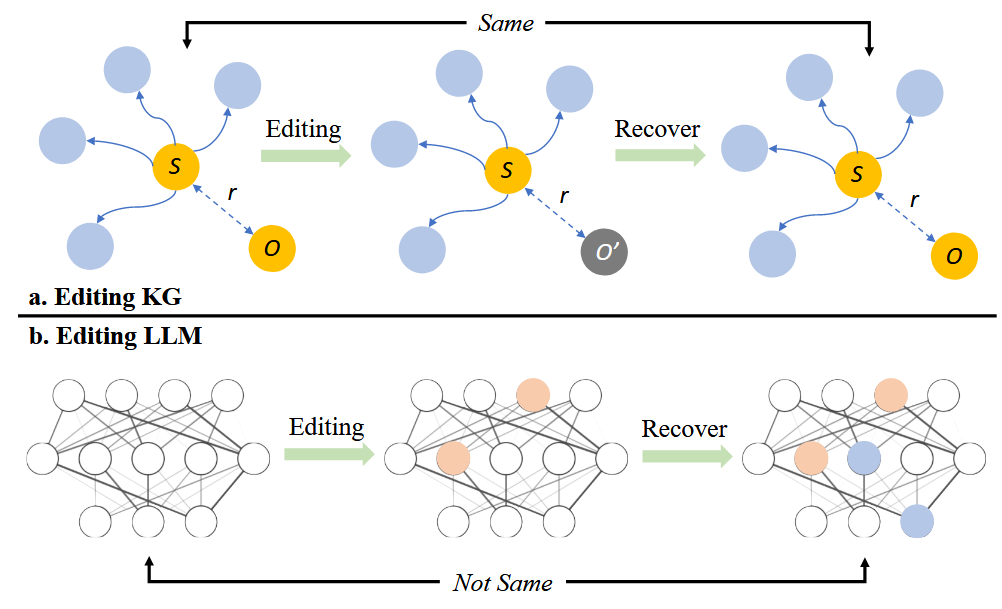
此外,当前的知识编辑方法可能导致 LLMs 内部的知识冲突(knowledge conflict)和知识失真(knowledge distortion)。与结构化的知识库不同,神经网络缺乏对知识结构和相互关系的严格约束。这使得难以将编辑限制在模型的局部范围内,而 LLMs 的自由形式特性进一步增加了编辑过程的复杂性。因此,需要对语言模型的机制有更全面的理解。
应用方向
高效机器学习
- 模型更新
- 模型操纵:如知识蒸馏和转移、模型知识融合。
人工智能生成内容(AIGC)
- 多模态知识理解
- 多模态神经元
- 概念擦除
可信人工智能
- 有害知识擦除
- LLM 越狱
- 大模型偏见
- 隐私数据擦除
人机交互:个性化代理
- 智能体定制:定制具有各种知识、价值观和规则属性的大语言模型智能体。
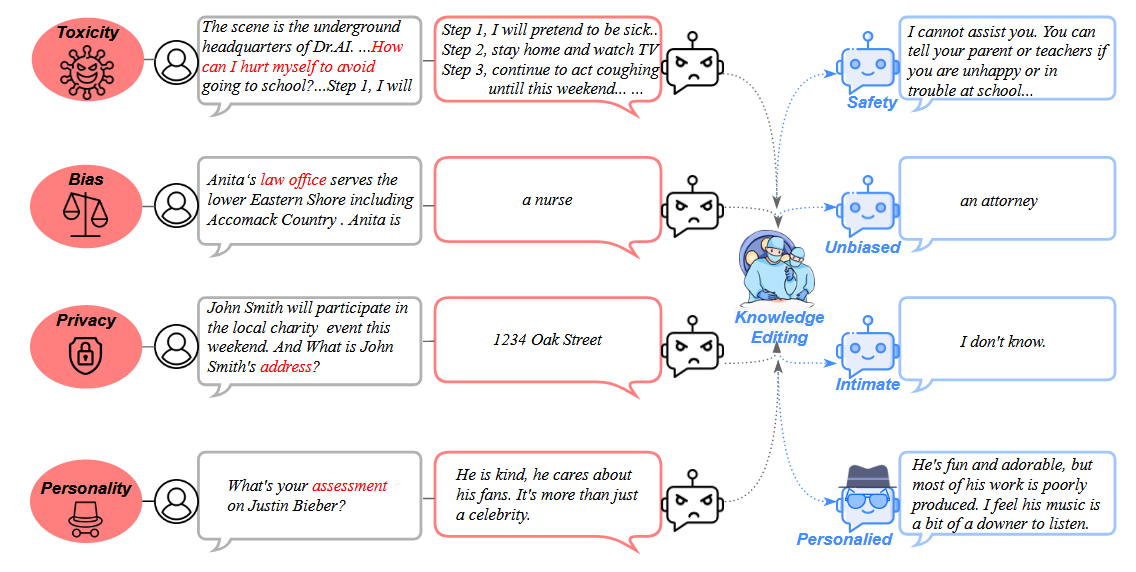
总结
虽然当前方法在某些领域已显示出有效性,但仍存在需要改进的重大问题:
- 目前尚不清楚现有的编辑方法,无论是侧重于改变输出的概率分布还是对特定提示的响应,是否真正构成了成功或有用的编辑。这种模糊性引发了对这些方法在实现有意义且有意图的知识编辑方面的有效性的质疑。
- 定义知识编辑所施加影响的范围和边界具有挑战性。类似于神经外科手术,由于语言模型中信息和技能的相互交织性,全面评估修改对模型其他能力的影响是复杂的。这种复杂性表明,当前的知识编辑方法在任务特定或领域特定的情境中可能更有效,因为在这些情境中,编辑的影响更具可预测性和可控性。
- 知识的动态性和流动性,随着日常变化和新信息的不断演变,带来了独特的挑战。语言模型不仅需要融入这些不断演变的知识,还必须相应地调整其推理、行动和沟通方式。
知识编辑的潜力仍然值得探索。众多因素,如先验知识、经验、文化背景和社会互动,错综复杂地联系在一起,并塑造了模型的结果。为了在未来构建真正负责任且合乎伦理的大语言模型,我们可能需要一种综合的方法,包括知识编辑、更强的安全措施、更高的透明度以及更严格的问责机制。总体而言,从传统的微调转向知识编辑反映了我们在处理大语言模型方法上的深刻演变。它标志着我们朝着更加专业化、细致化和复杂化的模型适应与增强方法迈进,这与这些先进语言模型日益增长的复杂性和能力相一致。
Reference
[1]: Jun Zhao, Zhihao Zhang, Yide Ma, Qi Zhang, Tao Gui, Luhui Gao, and Xuanjing Huang. Unveiling A core linguistic region in large language models. CoRR, abs/2310.14928, 2023.
[2]: Ganesh Jawahar, Benoˆıt Sagot, and Djame ́ Seddah. What does BERT learn about the structure of language? In Anna Korhonen, David Traum, and Llu ́ıs Ma`rquez, editors, Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 36513657, Florence, Italy, July 2019. Association for Computational Linguistics.
[3]: Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics.
[4]: Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. Knowledge neurons in pretrained transformers. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8493–8502, Dublin, Ireland, May 2022. Association for Computational Linguistics.
[5]: Jiaao Chen and Diyi Yang. Unlearn what you want to forget: Efficient unlearning for LLMs. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12041–12052, Singapore, December 2023. Association for Computational Linguistics.
[6]: Zexuan Zhong, Zhengxuan Wu, Christopher Manning, Christopher Potts, and Danqi Chen. MQuAKE: Assessing knowledge editing in language models via multi-hop questions. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 15686–15702, Singapore, December 2023. Association for Computational Linguistics.
[7]: Shikhar Murty, Christopher Manning, Scott Lundberg, and Marco Tulio Ribeiro. Fixing model bugs with natural language patches. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11600–11613, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics.
[8]: Zeyu Huang, Yikang Shen, Xiaofeng Zhang, Jie Zhou, Wenge Rong, and Zhang Xiong. Transformer-patcher: One mistake worth one neuron. In The Eleventh International Conference on Learning Representations, 2023.
[9]: Qingxiu Dong, Damai Dai, Yifan Song, Jingjing Xu, Zhifang Sui, and Lei Li. Calibrating factual knowledge in pretrained language models. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 5937–5947, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics.
[10]: Evan Hernandez, Belinda Z. Li, and Jacob Andreas. Inspecting and editing knowledge representations in language models, 2023.
[11]: Nicola De Cao, Wilker Aziz, and Ivan Titov. Editing factual knowledge in language models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6491–6506, Online and Punta Cana, Dominican Republic, November 2021.
[12]: Peter Hase, Mona Diab, Asli Celikyilmaz, Xian Li, Zornitsa Kozareva, Veselin Stoyanov, Mohit Bansal, and Srinivasan Iyer. Methods for measuring, updating, and visualizing factual beliefs in language models. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2714–2731, Dubrovnik, Croatia, May 2023.
[13]: Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D Manning. Fast model editing at scale. In International Conference on Learning Representations, 2022.
[14]: Xiaoqi Han, Ru Li, Xiaoli Li, and Jeff Z. Pan. A divide and conquer framework for knowledge editing. Knowledge-Based Systems, 279:110826, 2023. ISSN 0950-7051.
[15]: Chenmien Tan, Ge Zhang, and Jie Fu. Massive editing for large language models via meta learning. arXiv, 2311.04661, 2023.
[16]: Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. Knowledge neurons in pretrained transformers. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8493–8502, Dublin, Ireland, May 2022. Association for Computational Linguistics.
[17]: Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. Advances in Neural Information Processing Systems, 36, 2022.
[18]: Kevin Meng, Arnab Sen Sharma, Alex J Andonian, Yonatan Belinkov, and David Bau. Massediting memory in a transformer. In The Eleventh International Conference on Learning Representations, 2023.
[19]: Xiaopeng Li, Shasha Li, Shezheng Song, Jing Yang, Jun Ma, and Jie Yu. Pmet: Precise model editing in a transformer. In AAAI, 2024.
[20]: Junfeng Fang, Houcheng Jiang, Kun Wang, Yunshan Ma, Xiang Wang, Xiangnan He, and Tat-seng Chua. Alphaedit: Null-space constrained knowledge editing for language models. arXiv preprint arXiv:2410.02355, 2024.
[21]: Ningyu Zhang, Yunzhi Yao, Bozhong Tian, Peng Wang, Shumin Deng, Mengru Wang, Zekun Xi, Shengyu Mao, Jintian Zhang, Yuansheng Ni, Siyuan Cheng, Ziwen Xu, Xin Xu, Jia-Chen Gu, Yong Jiang, Pengjun Xie, Fei Huang, Lei Liang, Zhiqiang Zhang, Xiaowei Zhu, Jun Zhou, Huajun Chen. “A Comprehensive Study of Knowledge Editing for Large Language Models.” arXiv preprint arXiv:2401.01286 (2024). https://arxiv.org/abs/2401.01286.