Towards More Faithful Natural Language Explanation Using Multi-Level Contrastive Learning in VQA
一种新的基于自监督多层次对比学习的VQA自然语言解释模型 (MCLE),该模型具有语义级、图像级和实例级的事实和反事实样本。
MCLE提取判别特征,并将特征空间中的解释与视觉问题和答案对齐,以产生更一致的解释。作者进行了大量的实验和案例研究,以证明提出的方法在两个VQA-NLE基准上的有效性。
Proceedings of the AAAI Conference on Artificial Intelligence, 2024
摘要
视觉问答中的自然语言解释(VQA-NLE)旨在通过生成自然语言句子来解释模型的决策过程,以增加用户对黑箱系统的信任。
现有的事后分析方法在获得合理解释方面取得了重大进展。
然而,这种事后解释并不总是与人类的逻辑推理相一致,存在以下问题:
- 演绎不满意 (Deductive unsatisfiability):产生的解释在逻辑上不能导致答案;
- 事实不一致 (Factual inconsistency):模型在不考虑图像中的事实的情况下对答案的反事实解释进行证伪;
- 语义扰动不敏感 (Semantic perturbation insensitivity):模型不能识别微小扰动引起的语义变化。

这些问题降低了模型产生的解释的准确性。为了解决上述问题,作者提出了一种新的基于自监督多层次对比学习的VQA自然语言解释模型 (MCLE),该模型具有语义级、图像级和实例级的事实和反事实样本。
MCLE提取判别特征,并将特征空间中的解释与视觉问题和答案对齐,以产生更一致的解释。作者进行了大量的实验和案例研究,以证明提出的方法在两个VQA-NLE基准上的有效性。
方法
作者提出了基于多层次对比学习(MCLE)的自然语言解释框架。
MCLE 可以提高解释的可靠性,并加强解释与视觉问题答案之间的逻辑一致性。
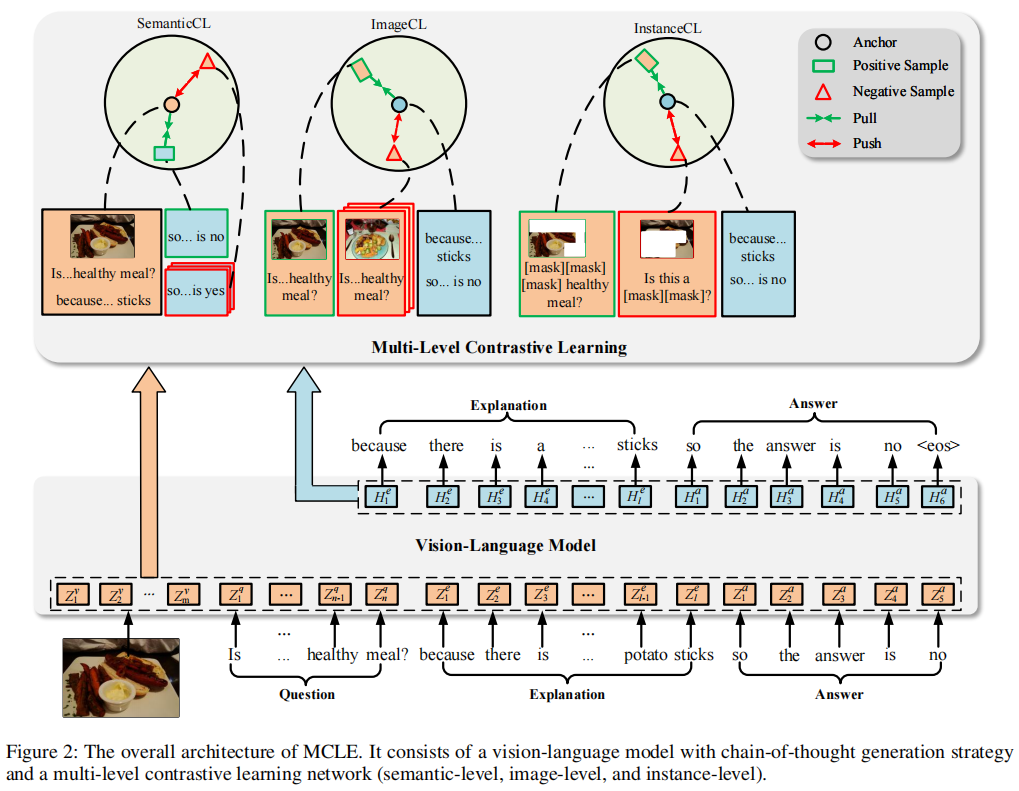
整体架构如下图所示,其中 MCLE 包括一个视觉语言模型和一个具有语义级、图像级和实例级的多级对比学习网络。
问题定义
给定一个图像 $V$ 和一个自然语言问题 $Q=(q_1, q_2, …, q_n)$,$q_i$ 表示第 $i$ 个词。
VQA-NLE 目标是生成相应的带有答案的自由文本解释。
文本和图像表示
基于前人的工作,作者采用在图片说明任务上预训练的 GPT-2 作为视觉语言模型, CLIP 作为图像编码器。
问题特征 $Z_Q$ 由 GPT-2 中对应的词嵌入层得到。图像特征 $Z_V$ 由CLIP编码得到。
思维链生成
为了减少解释和可视化问答之间的不一致,为VQA-NLE引入了思维链生成,它可以模拟导致答案的基本原理,并为决策过程提供一个可解释的窗口。
为了激发模型生成解释和答案,自然语言 “because” 和 “so the answer is” 分别作为解释和答案的前缀。
随后,从GPT-2的词嵌入层中得到前缀解释和前缀回答的特征,分别表示为 $Z_E$ 和 $Z_A$ ,连接后得到思维链特征 $Z_T=[Z_E;Z_A]$ 。
在训练过程中,所有输入作为一个序列输入到VL模型,通过交叉熵目标训练VL模型。
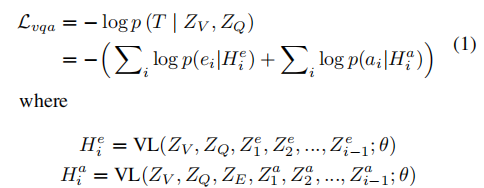
与其他事后方法不同,本文的解释生成完全基于视觉问题,不涉及基于答案的伪造解释。
此外,生成的解释可以用来提示答案的生成,从而提高了VQA-NLE的逻辑一致性。
多层次对比学习网络
多层次对比学习网络由三个模块组成:SemanticCL、ImageCL和InstanceCL。
遵循序列到序列学习的对比学习框架,作者最大化锚点与正(事实)序列之间的相似性,同时最小化锚点与负(反事实)序列之间的相似性,如下所示:
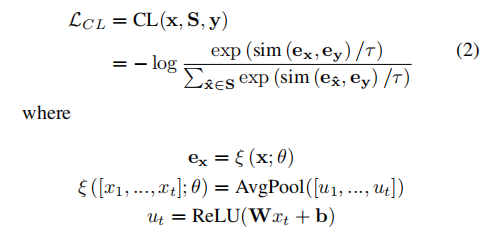
SemanticCL
为了指导VQA-NLE模型生成逻辑上导致答案的解释,作者设计了一个语义级CL模块 (SemanticCL)来学习解释和答案之间的关系。
具体而言,将真实答案序列作为正样本 $H_A$,随机采样同一批次的K个非目标答案 $\hat{H_A}$ 序列作为负样本集,
并将视觉问题与解释相结合作为锚点。对比损失定义如下:
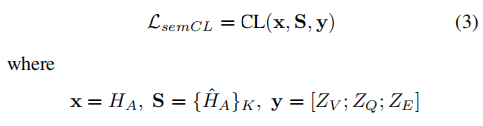
ImageCL
图像级CL模块 (ImageCL)旨在引导模型生成与视觉信息密切相关的解释,而不是仅根据问题伪造反事实解释。
具体而言,将解释与答案的组合作为锚点,将带有问题的原始图像作为事实样本,将带有问题的反事实图像作为反事实样本。
在反事实图像采样过程中,首先计算原始样本与数据集中其他样本之间的分数:
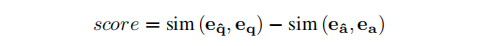
然后,选择得分最高的top-K样本中的图像作为反事实图像,这些图像与原始样本具有相似的问题,但答案不同,以引导模型感知视觉内容,消除语言偏见导致的事实不一致。
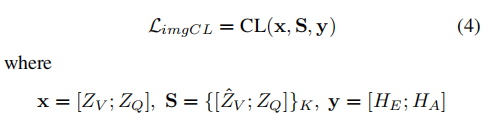
通过训练,解释接近相应的图像,而远离反事实图像。通过这种方式,ImageCL可以帮助学习解释和图像之间的判别性特征。
InstanceCL
为了帮助VQA-NLE模型感知由细粒度视觉或文本扰动引起的语义变化,作者设计了InstanceCL。采用Grad-CAM,通过以下函数推导出第$i$个对象和第$j$个单词对答案的贡献:

如果分数越高,则对象或词对答案的贡献越大。根据这些贡献分数,收集得分最高的前k个对象和单词作为事实样本,而反事实样本是通过屏蔽相应的事实样本生成的。
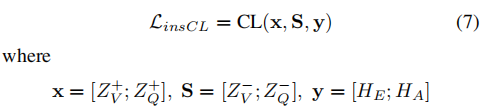
整体损失
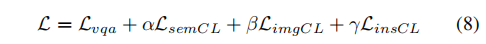
实验
数据集
对两个广泛使用的VQA-NLE基准进行了实证实验。
VQA-X是从VQA数据集中收集的,并为答案提供了额外的解释。
它由28K图像和33K问答对组成,分别分为29K/1.4K/1.9K用于训练、验证和测试。
A-OKVQA来自COCO数据集。
它包括大约25K个问题/答案/根本原因三元组,分别分为17.1K/1.1K/6.7K,用于训练、验证和测试。
评估指标
- 自动评估:利用BLUE、METEOR、ROUGE-L、SPICE和CIDEr等指标对生成的解释进行评估。预测的答案根据度量精度进行评估。
- 人工评估:确定每个生成的解释是否与答案一致,并从[yes, weak yes, weak no, no]中选择一个选项,分别对应得分[1, 2/3, 1/3, 0]。
主要结果
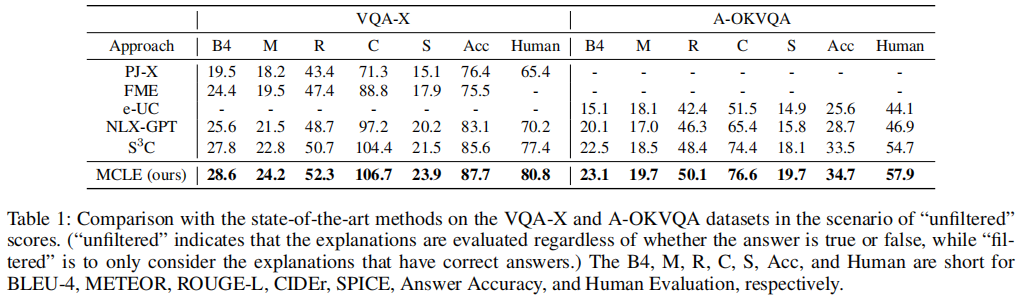
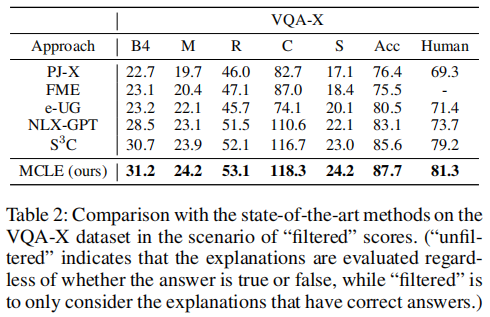
两个场景中都获得了最好的结果。这表明MCLE可以产生更可靠的解释。
关于答案的准确性,MCLE可以同时提高答案的准确性和相应的解释。MCLE在基线上的这些改进可归因于两个原因:
- MCLE采用具有思维链生成策略的解释-预测框架,可以模拟导致答案的基本原理;
- 多层次对比学习网络能够学习高质量的表征,引导模型生成逻辑一致性解释。
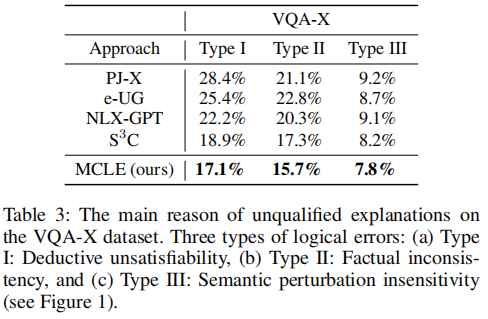
此外,作者还要求评估者选择VQA-X数据集上每个不合格解释的原因,在演绎不满意、事实不一致、语义扰动不敏感三个方面都达到了最低。
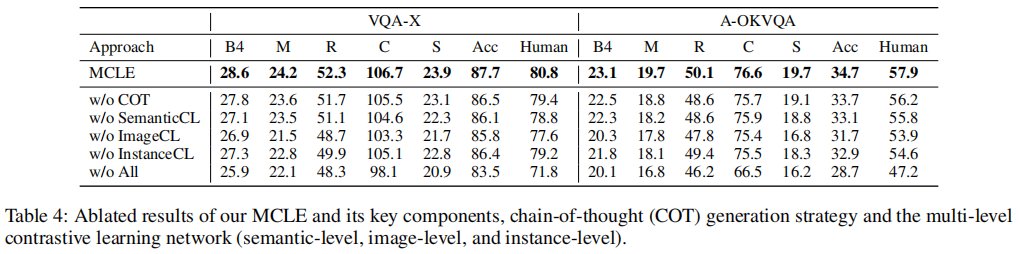
消融实验
案例分析

Towards More Faithful Natural Language Explanation Using Multi-Level Contrastive Learning in VQA