InstructPix2Pix: Learning to Follow Image Editing Instructions
We propose a method for editing images from human instructions: given an input image and a written instruction that tells the model what to do, our model follows these instructions to edit the image. To obtain training data for this problem, we combine the knowledge of two large pretrained models—a language model (GPT-3) and a text-to-image model (Stable Diffusion)—to generate a large dataset of image editing examples. Our conditional diffusion model, InstructPix2Pix, is trained on our generated data, and generalizes to real images and user-written instructions at inference time. Since it performs edits in the forward pass and does not require per-example fine-tuning or inversion, our model edits images quickly, in a matter of seconds. We show compelling editing results for a diverse collection of input images and written instructions.
Introduction
we propose an approach for generating a paired dataset that combines multiple large models pretrained on different modalities: a large language model (GPT-3) and a text-to-image model (Stable Diffusion). These two models capture complementary knowledge about language and images that can be combined to create paired training data for a task spanning both modalities.
Our model directly performs the image edit in the forward pass, and does not require any additional example images, full descriptions of the input/output images, or per-example finetuning.

Method
We treat instruction-based image editing as a supervised learning problem:
- first, we generate a paired training dataset of text editing instructions and images before/after the edit;
- then, we train an image editing diffusion model on this generated dataset

Generating a Multi-modal Training Dataset
Generating Instructions and Paired Captions
We first operate entirely in the text domain, where we leverage a large language model to take in image captions and produce editing instructions and the resulting text captions after the edit, as shown in Figure 2a.
See Table 1a for examples of our written instructions and output captions. Using this data, we fine-tuned the GPT-3 Davinci model for a single epoch using the default training parameters.
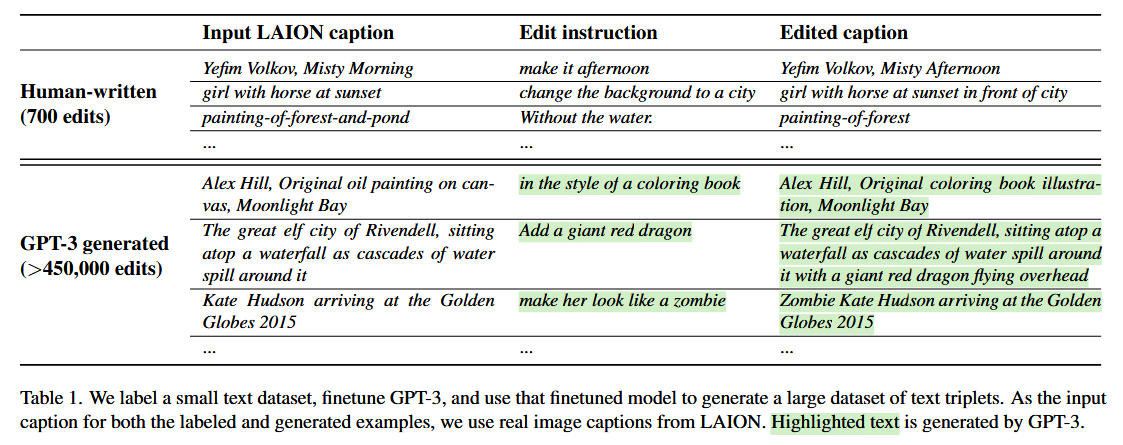
See Table 1b for example GPT-3 generated data. Our dataset is created by generating a large number of edits and output captions using this trained model, where the input captions are real image captions from LAION-Aesthetics (excluding samples with duplicate captions or duplicate image URLs).
Generating Paired Images from Paired Captions
One challenge in turning a pair of captions into a pair of corresponding images is that text-to-image models provide no guarantees about image consistency, even under very minor changes of the conditioning prompt.
We therefore use Prompt-to-Prompt, a recent method aimed at encouraging multiple generations from a text-to-image diffusion model to be similar.

While this greatly helps assimilate generated images, different edits may require different amounts of change in image-space. We therefore generate 100 sample pairs of images per caption-pair, each with a random $p ∼ \mathcal{U}(0.1, 0.9)$, and filter these samples by using a CLIP-based metric. This metric measures the consistency of the change between the two images (in CLIP space) with the change between the two image captions.
InstructPix2Pix
We use our generated training data to train a conditional diffusion model that edits images from written instructions. We base our model on Stable Diffusion, a large-scale text-to-image latent diffusion model.
Details about training referring to [1].
Results
We show instruction-based image editing results on a diverse set of real photographs and artwork, for many edit types and instruction wordings.



Limitations
While our method is able to produce a wide variety of compelling edits to images, including style, medium, and other contextual changes, there still remain a number of limitations:
- Our model is limited by the visual quality of the generated dataset, and therefore by the diffusion model used to generate the imagery.
- Furthermore, our method’s ability to generalize to new edits and make correct associations between visual changes and text instructions is limited by the human-written instructions used to fine-tune GPT-3, by the ability of GPT-3 to create instructions and modify captions, and by the ability of Prompt-to-Prompt to modify generated images.
- Additionally, we find that performing many sequential edits sometimes causes accumulating artifacts.
- Furthermore, there are well-documented biases in the data and the pretrained models that our method is based upon. The edited images from our method may inherit these biases or introduce others.
References
[1]: Tim Brooks, Aleksander Holynski, Alexei A. Efros. InstructPix2Pix: Learning To Follow Image Editing Instructions. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 18392-18402
InstructPix2Pix: Learning to Follow Image Editing Instructions