DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
In this work, we present a new approach for “personalization” of text-to-image diffusion models. Given as input just a few images of a subject, we fine-tune a pretrained text-to-image model such that it learns to bind a unique identifier with that specific subject. Once the subject is embedded in the output domain of the model, the unique identifier can be used to synthesize novel photorealistic images of the subject contextualized in different scenes. By leveraging the semantic prior embedded in the model with a new autogenous class-specific prior preservation loss, our technique enables synthesizing the subject in diverse scenes, poses, views and lighting conditions that do not appear in the reference images.
Introduction

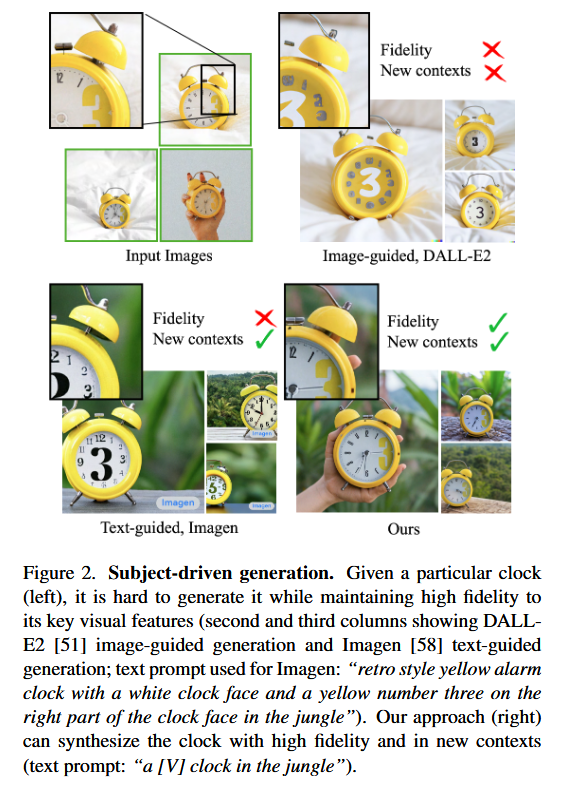
A new approach for personalizing large text-to-image diffusion models enables them to generate specific subjects in various contexts. While current models create diverse images from text, they struggle to replicate exact appearances. This method introduces a rare token identifier for each subject, fine-tunes the model with both images and text, and applies a class-specific prior preservation loss to prevent overfitting. This allows the model to synthesize photorealistic images of the subject while maintaining its key features across different scenes (Figure 2).
Method
Text-to-Image Diffusion Models
Diffusion models are probabilistic generative models that are trained to learn a data distribution by the gradual denoising of a variable sampled from a Gaussian distribution. They are trained using a squared error loss to denoise a variably-noised image or latent code $z_t := \alpha_tx + \sigma_t\epsilon$ as follows:
$$
\mathbb{E}_{x, c ,\epsilon, t}\left[ w_t \Vert \hat{x}_\theta(\alpha_tx + \sigma_t\epsilon, c) - x \Vert^2_2 \right] \tag{1}
$$
details about the loss function referring to Diffusion Models: A Comprehensive Survey of Methods and Applications - Breynald Shelter.
Personalization of Text-to-Image Models
Our first task is to implant the subject instance into the output domain of the model such that we can query the model for varied novel images of the subject.
Designing Prompts for Few-Shot Personalization
In order to bypass the overhead of writing detailed image descriptions for a given image set we opt for a simpler approach and label all input images of the subject “a [identifier] [class noun]”, where [identifier] is a unique identifier linked to the subject and [class noun] is a coarse class descriptor of the subject (e.g. cat, dog, watch, etc.).
In essence, we seek to leverage the model’s prior of the specific class and entangle it with the embedding of our subject’s unique identifier so we can leverage the visual prior to generate new poses and articulations of the subject in different contexts.
Rare-token Identifiers
Our approach is to find rare tokens in the vocabulary, and then invert these tokens into text space, in order to minimize the probability of the identifier having a strong prior. We perform a rare-token lookup in the vocabulary and obtain a sequence of rare token identifiers $f (\hat{V})$, where f is a tokenizer; a function that maps character sequences to tokens and $\hat{V}$ is the decoded text stemming from the tokens $f (\hat{V})$.
Class-specific Prior Preservation Loss
To mitigate the two aforementioned issues during fine-tuning:
- Model slowly forgets how to generate subjects of the same class as the target subject;
- The possibility of reduced output diversity.
we propose an autogenous class-specific prior preservation loss that encourages diversity and counters language drift. In essence, our method is to supervise the model with its own generated samples, in order for it to retain the prior once the few-shot fine-tuning begins.
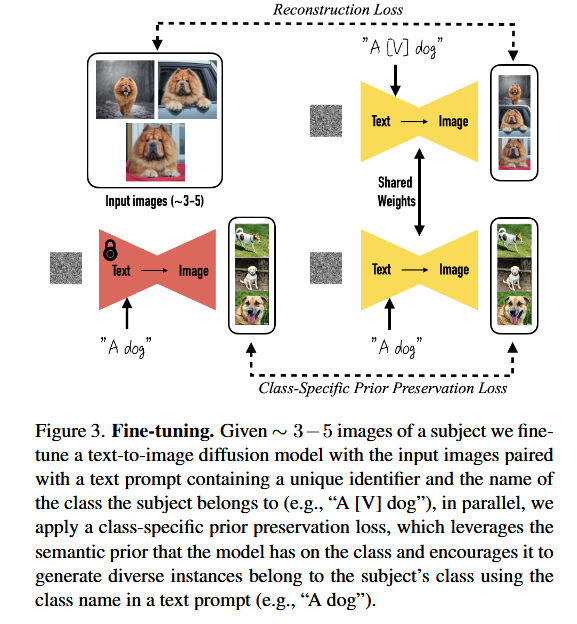
Specifically, we generate data $x_{pr} = \hat{x}(z_{t1} , c_{pr})$ by using the ancestral sampler on the frozen pre-trained diffusion model with random initial noise $z_{t1} \sim \mathcal{N} (0, I)$ and conditioning vector $c_{pr} := \Gamma(f (“a [class noun]”))$. The loss becomes:
$$
\mathbb{E}_{x, c ,\epsilon, \epsilon’, t}\left[ w_t \Vert \hat{x}_\theta(\alpha_tx + \sigma_t\epsilon, c) - x \Vert^2_2 \right] + \left[ \lambda w_{t’} \Vert \hat{x}_\theta(\alpha_{t’}x_{pr} + \sigma_{t’}\epsilon’, c_{pr}) - x_{pr} \Vert^2_2 \right] \tag{2}
$$
where the second term is the prior-preservation term that supervises the model with its own generated images, and $\lambda$ controls for the relative weight of this term.
Expreiments
Comparisons with Textual Inversion
We compare our results with Textual Inversion, the recent concurrent work of Gal et al., using the hyperparameters provided in their work. We find that this work is the only comparable work in the literature that is subjectdriven, text-guided and generates novel images. We generate images for DreamBooth using Imagen, DreamBooth using Stable Diffusion and Textual Inversion using Stable Diffusion.

We compute DINO and CLIP-I subject fidelity metrics and the CLIP-T prompt fidelity metric. In Table 1 we show sizeable gaps in both subject and prompt fidelity metrics for DreamBooth over Textual Inversion.
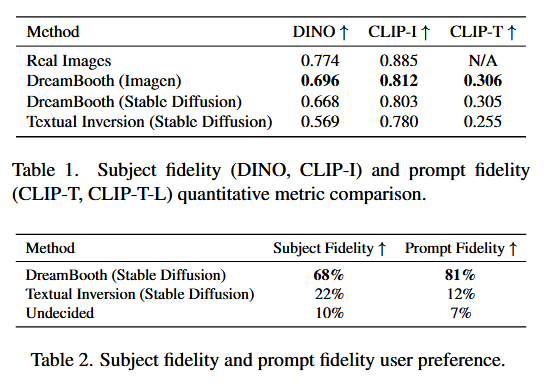
Further, we compare Textual Inversion (Stable Diffusion) and DreamBooth (Stable Diffusion) by conducting a user study. We average results using majority voting and present them in Table 2. We find an overwhelming preference for DreamBooth for both subject fidelity and prompt fidelity.
Prior Preservation Loss Ablation
The prior preservation loss seeks to combat language drift and preserve the prior. We compute a prior preservation metric (PRES) by computing the average pairwise DINO embeddings between generated images of random subjects of the prior class and real images of our specific subject. The higher this metric, the more similar random subjects of the class are to our specific subject, indicating collapse of the prior.
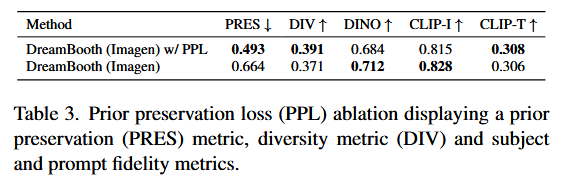
Additionally, we compute a diversity metric (DIV) using the average LPIPS cosine similarity between generated images of same subject with same prompt. We observe that our model trained with PPL achieves higher diversity (with slightly diminished subject fidelity), which can also be observed qualitatively in Figure 5, where our model trained with PPL overfits less to the environment of the reference images and can generate the dog in more diverse poses and articulations.

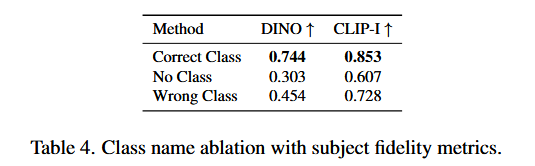
Class-Prior Ablation
We finetune Imagen on a subset of our dataset subjects (5 subjects) with no class noun, a randomly sampled incorrect class noun, and the correct class noun. Subject fidelity results are shown in Table 4, with substantially higher subject fidelity for our proposed approach.
Applications
Recontextualization

Art Renditions & Property Modification

Limitations
We illustrate some failure models of our method in Figure 8. The first is related to not being able to accurately generate the prompted context. Possible reasons are a weak prior for these contexts, or difficulty in generating both the subject and specified concept together due to low probability of co-occurrence in the training set. The second is context-appearance entanglement, where the appearance of the subject changes due to the prompted context, exemplified in Figure 8 with color changes of the backpack. Third, we also observe overfitting to the real images that happen when the prompt is similar to the original setting in which the subject was seen.

Other limitations are that some subjects are easier to learn than others (e.g. dogs and cats). Occasionally, with subjects that are rarer, the model is unable to support as many subject variations. Finally, there is also variability in the fidelity of the subject and some generated images might contain hallucinated subject features, depending on the strength of the model prior, and the complexity of the semantic modification.
References
[1]: Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, Kfir Aberman. DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 22500-22510
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation